blog
- I use DayOne on my iPhone, iPad, Apple Watch, and the web. Journal is only on the iPhone.
- DayOne is my memory archive. I can search for entries with many attributes (like dates), while also organizing with tags and separate journals. Plus, the On This Day feature is great for revisiting old entries. Journal only lets you filter by entry type. There is no search feature.
- There are many ways to get content into DayOne, including via Shortcuts. Journal is much less accommodating and, oddly, has no Shortcuts support. A related feature in DayOne is templates, which I use frequently and Journal lacks.
- Given how valuable (to me) content is in DayOne, I appreciate the broad set of export features. Best I can tell, there’s no way to export from Journal.
- 📰 RSS: I’ve swapped out Feedbin for iCloud as the backend for NetNewsWire. Although I really like the Feedbin service, my primary use of it is to access my feeds via a web browser at work. In an attempt to limit my feed reading to just once in the morning and once in the evening, switching to iCloud means that only my personal iPhone has access.
- 👓 Read It Later: Switching to Safari’s Reading List for this. The feature is well integrated into the system and more than sufficient for my needs.
- 🎧 Podcasts: After some back and forth and back again, over to Apple Podcasts.
- 🏃♂️Fitness: As I wrote about recently, I use HealthFit (mostly) instead of Apple Fitness
- 🧘 Meditation: Waking Up, instead of Mindfulness
- 📓 Journal: Doesn’t count yet, since Apple hasn’t released their journalling app. Soon, though, DayOne instead of the default
- 📚 Books: Libby instead of Apple Books, mostly because of the public library integration
- 🎸 Listen later: MusicBox instead of the Apple Music library
- ✉️ Mail Client: Apple Mail
- 📨 Mail Server: iCloud Custom Email Domain
- 📝 Notes: Apple Notes
- ✅ To-Do: Reminders
- 📷 iPhone Photo Shooting: Camera.app
- 📚 Photo Management: Photos.app
- 🗓️ Calendar: Calendar.app
- 🗄️ Cloud file storage: iCloud
- 📰 RSS: NetNewsWire connected to Feedbin
- 📇 Contacts: Contacts.app
- 🕸️ Browser: Safari
- 💬 Chat: iMessage, WhatsApp
- 🔖 Bookmarks: Micro.blog
- 👓 Read It Later: Micro.blog
- 📜 Word Processing: Pages
- 📊 Spreadsheets: Numbers
- 🛝 Presentations: Keynote
- 🛒 Shopping Lists: Reminders
- 🧑🍳 Meal Planning: None
- 💰 Budgeting & Personal Finance: ScotiaBank app
- 🗞️ News: The Economist
- 🎶 Music: Apple Music
- 🎧 Podcasts: Overcast (though testing Podcasts.app again)
- 🔐 Password Management: 1Password (likely changing to iCloud Keychain)
- Available on the Apple Watch, ideally as a first class app, rather than just presenting data from the phone
- Suitable for multisport. I’ll consider a highly specialized app, though prefer one that covers at least running, cycling, and swimming
- Consolidated and local data. I prefer one location for all of the data and certainly not locked into a web service
- Apple Health stores all of my data. Not really an app, rather this is the foundational data store that integrates across all sources
- The Apple Workout app records my workouts. Although there are some better, specialized apps, pressing the Action Button on my Ultra and starting a workout is so convenient that I’m sticking with Workout. The onscreen stats on the watch are more than sufficient for my needs
- HealthFit is for viewing workout data and general fitness trends. I prefer HealthFit’s details to Apple Health’s. As the screenshots below demonstrate, HealthFit provides useful overviews of everything I’ve done recently. I also use HealthFit to selectively send completed workouts to Strava
- Strava is for my local community. Seeing what my friends are up to and cheering them on is part of staying motivated for the training. Strava does have a good set of statistics and summaries. Overall, though, I prefer HealthFit’s design and privacy
- Recover sends me targeted mobility and recovery sessions, based on my recent activity. This is the only reason I’m currently paying for a Strava subscription. However, Strava is rather expensive if this is all I’m paying for and Recover breaks principles 1 and 3. So, I don’t think this one will last much longer
- Training Peaks is exclusively for getting workouts from my coach. There’s way more potential with this app. I’m just not using any of it
- Training Today keeps track of my readiness to train. I’ve written about it before and still consult it regularly
- Zwift Companion is well named. I use it to join Zwift events and as a second screen while Zwifting.
- We made the choice on her behalf. Of course, we made the choice to reduce her suffering, but it was still an active choice for which we were accountable.
- Our kids were young enough to not have experienced much loss yet, while also old enough to understand what was happening. Explaining to them why this was the best outcome was difficult.
- Wetsuit: $400 for the Nineteen Pipeline a decent entry level model
- Swim equipment: $200 for a bathing suit, flutter board, goggles, swim cap, and other gear
- Swim buddy: $70 and important if doing any open water swimming. Provides visibility for boaters, something to hold onto if you need a rest, and some storage space
- Swimming fees: $100 for access to a local municipal pool for a few months. A common alternative is to join a swim club, which would be more expensive, but would also include coaching and community support
- Before investing in a bike, I invested $200 in a bike sizing session. No point in buying a bike that didn’t fit!
- Bike: Of all the items in the budget, this is both the most expensive and the most variable. You can spend $15,000 on a fancy bike or get by with a used one in the few hundred dollar range. This Trek for $2,500 both fit my needs and was actually available (COVID-induced shortages wreaked havoc on bike supply chains)
- Turns out that fancy bikes don’t come with pedals, so another $200 for those and $300 for shoes
- Also, based on the bike fit, I swapped out the handlebars with another set for $200, plus aero bars for $300
- Another $500 for clothes, water bottles, bottle cages, and a repair kit
- Given I started training in the winter, I added an indoor trainer for $1,000
- Bike computer: $400 for the Garmin Edge 130. Since I was already tracking metrics via my Apple Watch and iPhone, I kept this one simple, mostly just to have easily visible metrics during long rides on the weekend
- This one is pretty easy, two sets of running shoes at about $200 each
- Trisuit: $200
- Registration fee for the event: $500
- Accommodations for three days: $1,000. This one is obviously pretty variable, based on the event location
- A coach for 6 months at $280/month and worth every penny
🏃♂️ Dynamic run training in Training Today
I’ve been using Training Today for a while now to track my readiness to train (RTT). They’ve recently released a new feature that provides dynamic training for running based on RTT which takes into account your current recovery and health to make sure you don’t overtrain.
Generating the workouts is easy. In the iPhone app, you choose the type of run (speed, endurance, recovery, etc) and then the app shows you the structured workout, targeting your current RTT. There are options to adjust the RTT (though that seems like cheating) and to shorten the run, if you’re pressed for time. Once you select “Create Workout”, the run is sent to your Apple Watch.
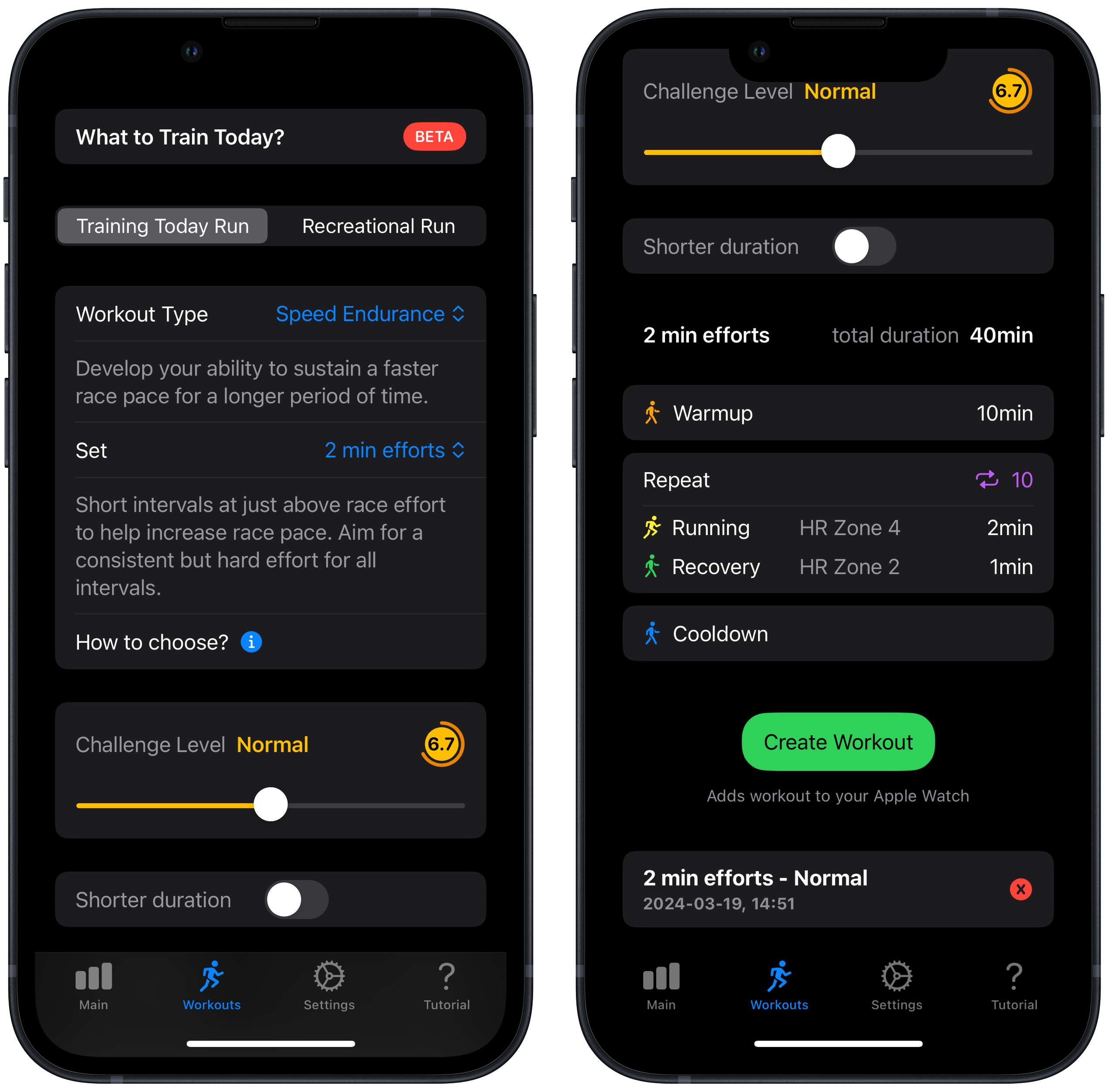
On the watch, the Training Today workout shows up near the top of the list in the Workout app and behaves like any other workout. The interval times and heart rate zones with alerts are passed along, making it easy to follow the workout.

There are a few obvious enhancements, which the developers have already promised. The first is the addition of cycling and swimming workouts. The second is creating actual fitness plans across multiple days.
I’m really intrigued by an app like Training Today. Our smartwatches are continuously monitoring us and tracking our fitness. Why not have them also program tailored workouts? That said, I have an actual triathlon coach that creates a comprehensive fitness plan while also providing expert advice and motivation. My watch isn’t this sophisticated — yet.
Trying to avoid Apple’s Journal app 📔
I have 9,698 entries in DayOne across 4,312 days. This is one of my favourite and most consistently used apps. And, yet, somehow I am tempted to switch to Apple’s Journal app. This post is to remind me why that is a bad idea.
So, here’s a list of DayOne features I use that Journal doesn’t have:
Given all of this, why am I drawn to Journal?
The primary answer is an appeal to simplicity (which Journal certainly has). I do worry sometimes that my structure of separate journals, tags, and templates in DayOne is unecessary complexity. A secondary answer is my policy of favouring default apps when they’re good enough. Journal is likely quite adequate for many people, especially those that journal to get ideas out of their heads, rather than as a memory archive that they review.
Having written this down, the answer seems clear: keep using DayOne. Perhaps, though, I should revisit my DayOne structure to get some of that appealing simplicity from Journal.
Investing in the MacSparky Productivity Field Guide ✅
There is absolutely no shortage of productivity methods and content out there, especially in the “influencer” racket. I’m quite sure that there is no one true way to be productive. In fact, I think there’s some merit to switching up my approach on occasion, just to reinvigorate my interest.
To that end, I’ve really appreciated the MacSparky Productivity Field Guide. I find the roles based approach suits me really well, as I try to juggle multiple parts of my life, while the intentionality it creates helps with prioritizing and staying engaged. This isn’t about any particular tasks app or zettelkasten setup. Rather, the emphasis is on the why and making tough choices about where to focus attention.
There aren’t many “quick wins” here. In following along, I had to think carefully, document my intentions, and track all of my commitments over a few weeks. All well worth doing and now paying off. As with so many things, upfront investments payoff in the long run.
🏊♂️🚴♂️🏃♂️ Fitness in 2023
I kept busy in 2023 with triathlon training. As a reference point for next year, here’s a comparison of 2023 with 2022.
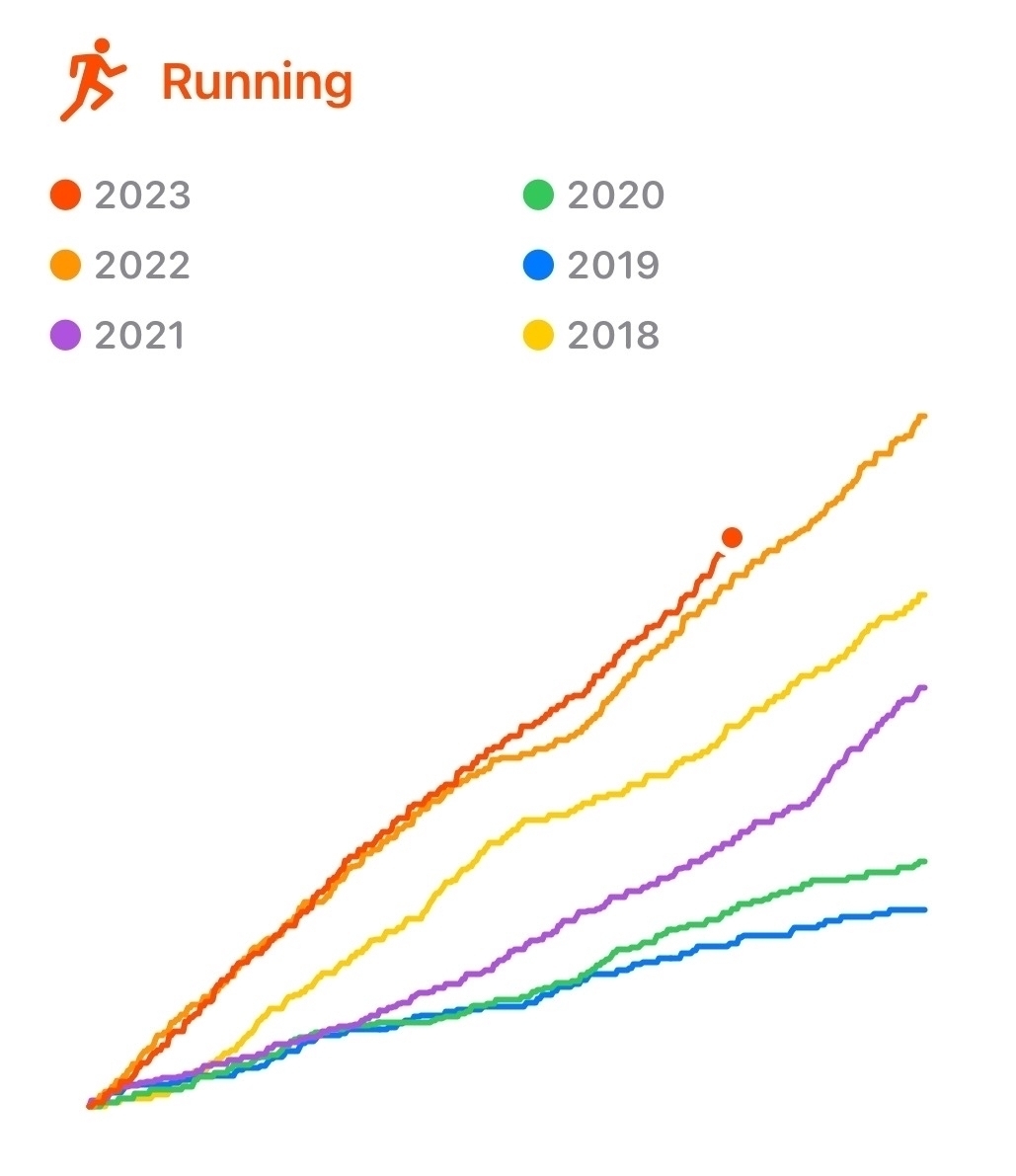
My running was surprisingly consistent. Although the totals are almost identical, I do think that my structured workouts were much better in 2023. Each run had a purpose and all were part of a bigger plan.
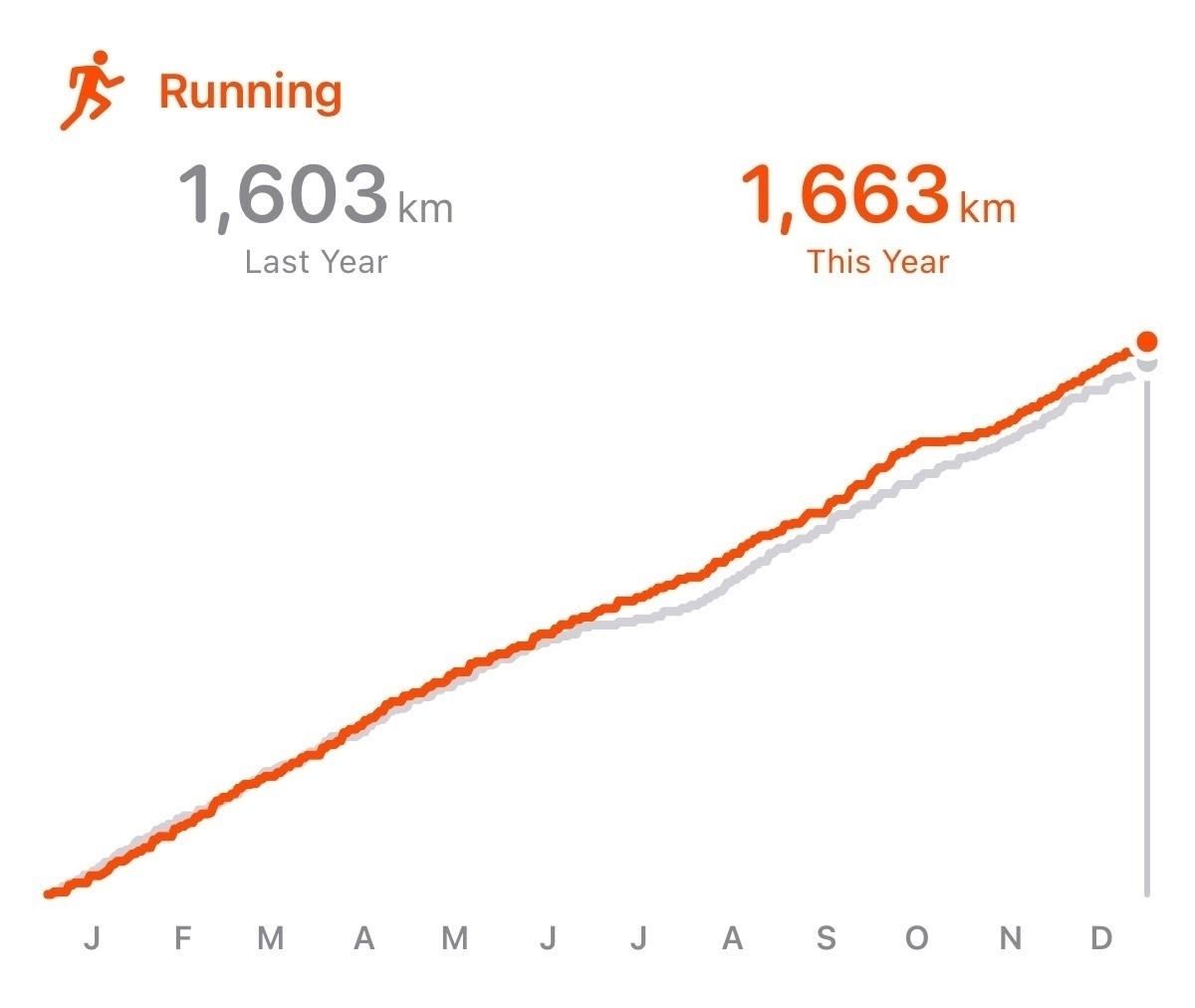
There was a trade off for cycling between indoors and outdoors. In 2023, I couldn’t quite get aligned with most of the outdoor group rides. So, there was a lot more indoor riding on Zwift. I’d like to switch this around in 2024.
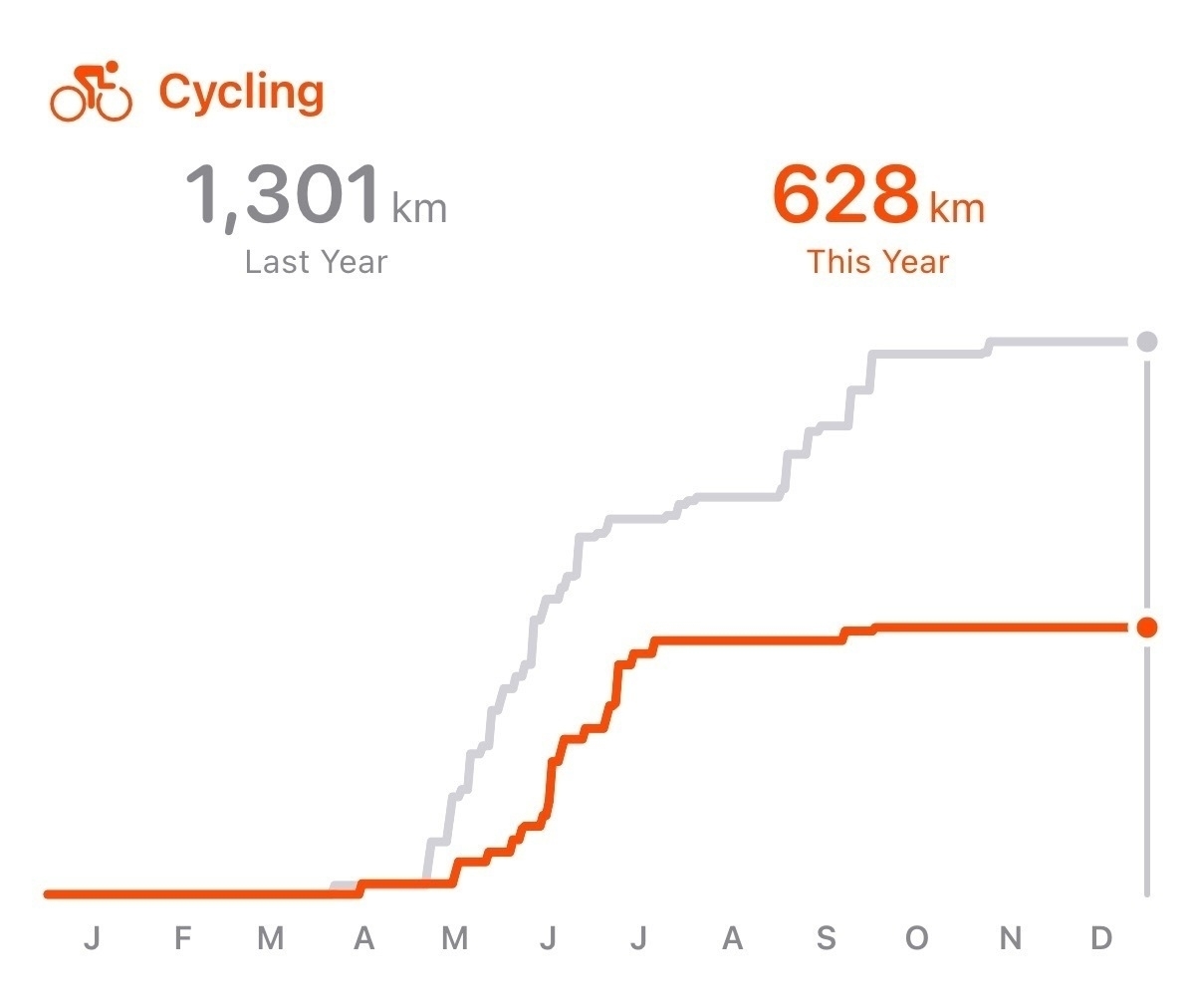
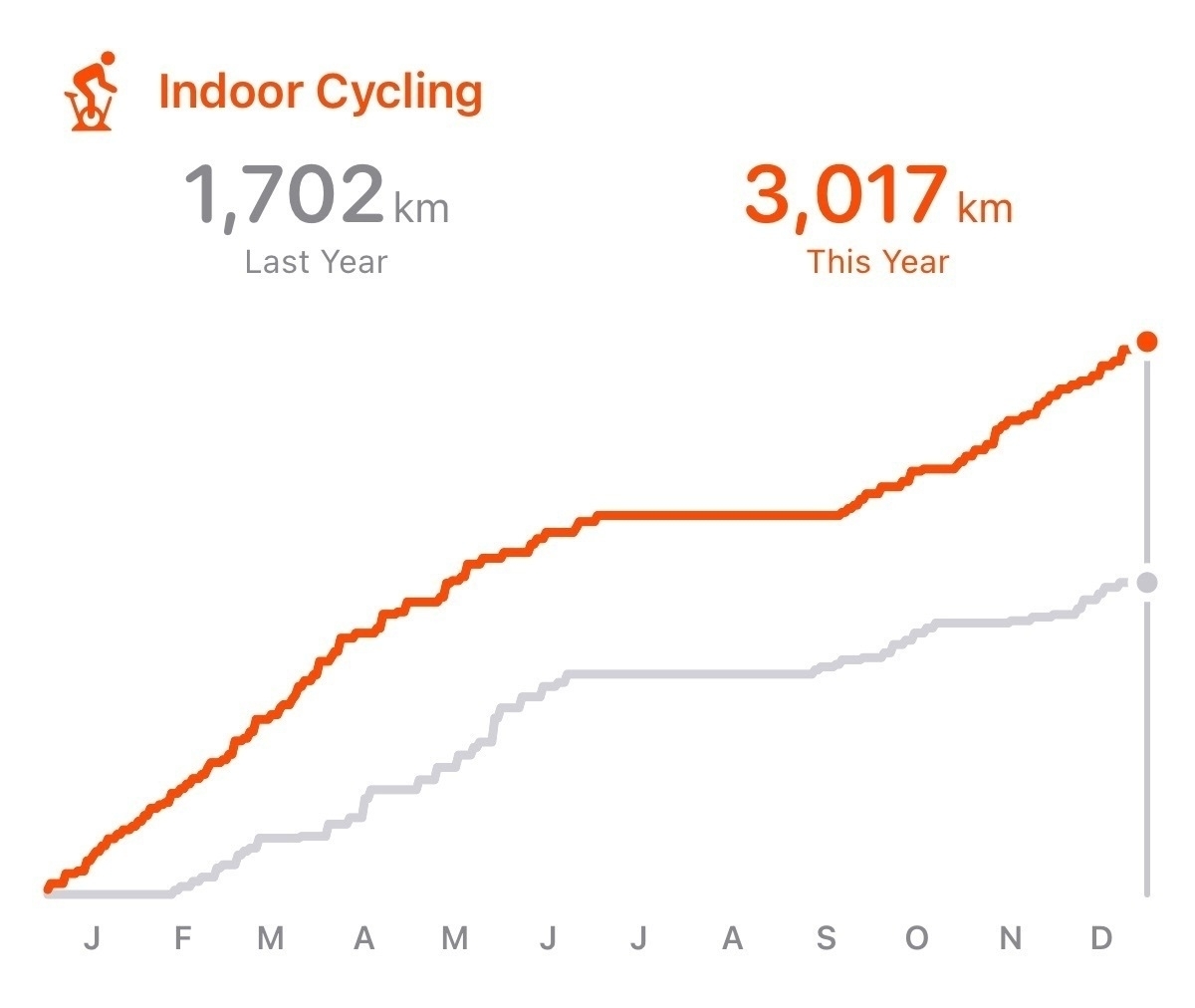
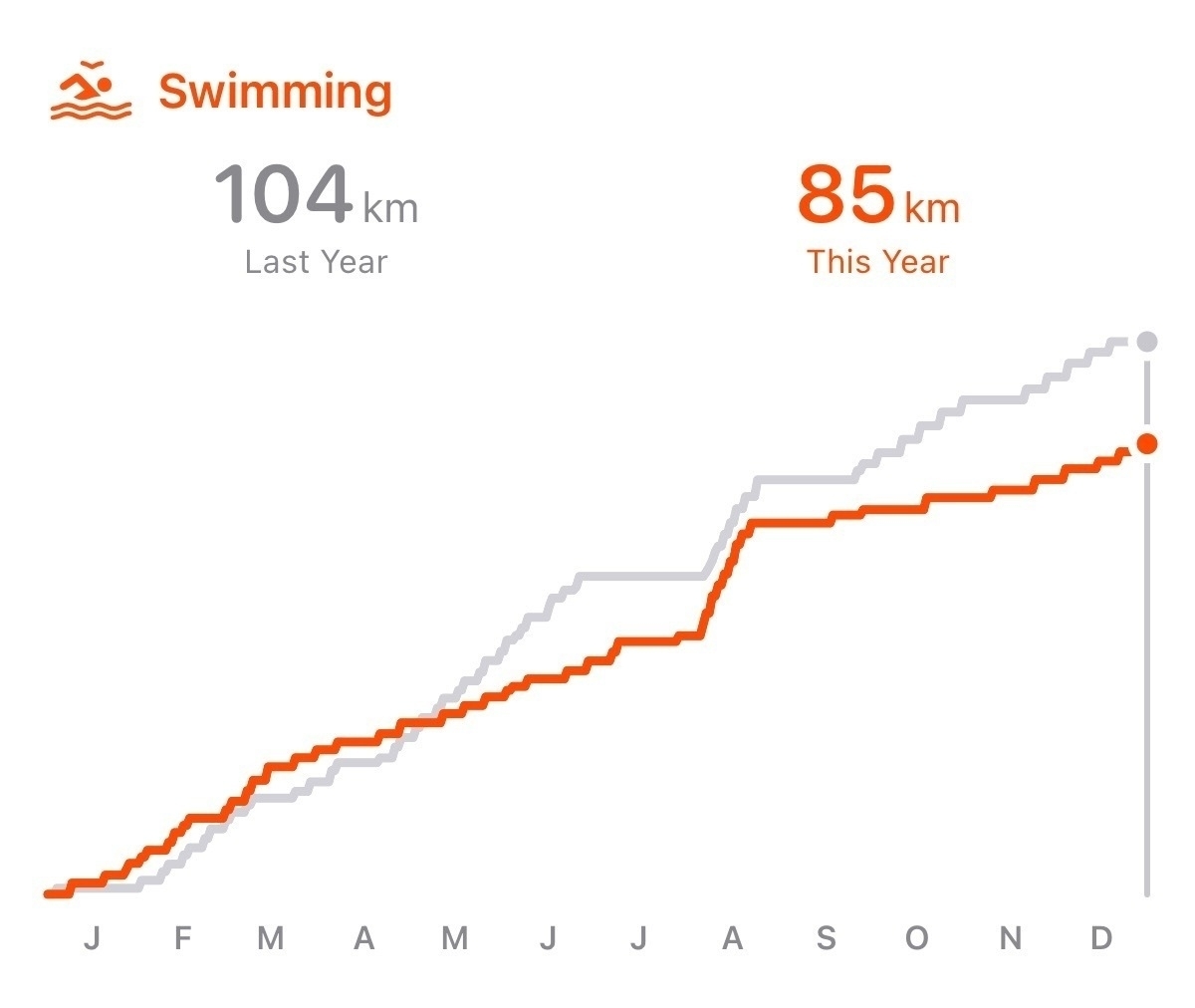
I’m surprised by my relatively low swimming distances in 2023. This is my strongest of the three. So, I tend to take it for granted. I should bump this up in 2024.
Year in books for 2023
I read some great books in 2023.
My favourite fiction book was The Mountain in the Sea by Ray Nayler. Non-fiction was Enemy of All Mankind by Steven Johnson.









































Even more defaults
As a follow up to my Duel of the Defaults post, I’ve made a few changes. These are all based on further adopting app defaults to simplify things.
These choices are largely motivated by an attempt to limit the number of inputs and potential for distractions. That said, these default apps are still powerful and effective.
Non-default apps
As a follow up to my list of default apps, I have a few non-default apps that weren’t on the original list from Hemispheric Views.
Duel of the Defaults: My List
Episode 097 of the Hemispheric Views podcast held a fun Duel of the Defaults! competition.
Here’s my list. I’ve really shifted to defaults over the past year. I’m conflicted about this: I really like a good indie app, yet find my needs don’t justify the complexity of using non-defaults.
Choosing a portfolio of fitness apps 🏊♂️🚴♂️🏃♂️
There’s a bewildering array of fitness apps out there. Here’s an attempt to document what I’m currently using.
I have some criteria when considering a fitness app:
With these in mind, my current portfolio of fitness apps is:
That’s currently it for the portfolio. Being able to consolidate all of my data into Apple Health really frees me up to try new apps without worrying about data lock in. Despite this freedom, I’m comfortable with the current set and don’t plan to switch things up anytime soon.
🚂 Importance of Transportation Funding: Framing the Issues
Discussions about transit often end up about funding. To help make these discussions productive, I was pleased to co-author a paper through the Transportation Association of Canada titled Importance of Transportation Funding: Framing the Issues.
Working on this with David Kriger, Nick Lovett, Yonghai Xiao, Vahid Ayan, Andrew Devlin, Tamim Raad, and Haytham Sadeq was delightful.
Here’s the abstract:
Transportation funding is becoming an important topic of discussion at all levels of Transportation Association of Canada (TAC) councils and committees, reflecting discussions that are taking place throughout the Canadian transportation community. The fundamental needs are to maintain and upgrade the country’s aging transportation system while adding new infrastructure to meet the demands of a growing population and economy. These needs are evolving in the face of new challenges, notably changing funding sources and priorities, climate change impacts on infrastructure resiliency, changes to how the system is used, and accommodating new transportation and communications technologies. These challenges have become sharper with the COVID-19 pandemic-induced disruptions in how people and goods move and in shifts in revenues and funding priorities. These needs and challenges cover a broad range. They vary across the country, by mode, ownership, responsibility and more. All told, these complexities mean that the needs and challenges are not fully understood. This briefing describes and categorizes these key challenges and opportunities and provides an initial, high-level assessment of the broader range of potential funding sources, approaches and needs. From this review, the briefing identifies knowledge gaps and potential research directions for consideration by the TAC Transportation Finance Committee and other committees and councils to address these gaps.
Switching podcast apps, again 🎧
As predicted, after a couple of months with the Apple Podcasts app, I’m back to Overcast.
I think that Apple’s Podcasts app is great for anyone new to podcasts, given it has a strong focus on discovering new shows. I’m looking for a podcast app that simply plays my carefully curated, short list of podcasts. With Apple Podcasts, I kept finding new episodes of shows I didn’t intend to subscribe to in my queue.
Adding in the nice audio features in Overcast that boosts voices and trims silences, makes Overcast the right app for me.
Of course, having just made this decision and rebuilt my Overcast subscriptions, I see that Apple has now integrated Apple Music into their Podcasts app. Better ways of managing radio episodes in Apple Music is on my list of features I’d like to see. So, looks like I’m not actually settled on a podcasts app yet, which was a silly hope anyway.






Huntsville 70.3 Ironman notes 🏊♂️🚴♂️🏃♂️
After a few weeks of recovery, here are a few notes on the Huntsville 70.3 Ironman.
The short version (given there’s lots of details below) is that the course was fantastic, though very hilly, and I managed to shave 15 minutes from my last 70.3.
Pre-race
No surprises here. There were scheduled times for registration and all we needed was the receipt from our online payment. With that, they handed over a wristband, timing chip, stickers for my bike and helmet, a hot-pink swim cap for my age group, t-shirt, and a morning gear bag for transferring clothing from the swim start to the run finish.
Next up was dropping my bike off at the transition. There were two stickers for the bike, both of which had my bib number on them and matched the number on my wristband. Staff at the transition entrance used these to make sure the bike belonged to me, before letting me in. Then I tracked down my transition spot, which was nicely equidistant from the swim, bike, and run entrances.
That was it for the Saturday events, other than eating some tasty Thai food and getting a good night’s sleep. Sunday (race day) started early, so that I could set up my transition area by 6:30. I took about 10 minutes to get everything organized and visualize how I’d move through the zone.
Swim
We were organized into age groups for the swim start. As one of the older groups, we started 20 minutes after the first wave. We waded into the lake and floated around the start line, until they announced our group and we started swimming.
The water was a nice, cool temperature and I felt good throughout. The last third of the swim was in the river between Fairy Lake and Lake Vernon. So, we got pretty crowded and had to manage a fair bit of contact.
In previous triathlons, I’ve had trouble with dizziness when getting out of the water. This time I increased my rate of kicking for the last five minutes or so to get the blood moving around again. This seemed to really help and I had no issues with being light headed this time.
The swim ended with a long 500m run along pavement into the transition zone. During this, I was able to wiggle out of the top half of my wetsuit, in preparation for the rest of the transition. Once I was at my transition spot, I pulled off the wetsuit and quickly consumed one caffeinated gel. Then helmet and bike shoes on, and grabbed the bike to run out to the bike mount line.
Bike
There was light rain during the swim which left the start of the bike course a bit wet and slippery. After a kilometre or so, that dried off and the bike course was gorgeous with lots of hills through the Canadian Shield. By the end, we’d accumulated 1,100 m of elevation and it was important to manage the effort and not burn out. I stuck with a heart rate target of 155 for most of the course with a few exceptions for the bigger hills. That left me with lots of energy for the run after about 2 hours and 50 minutes of riding.
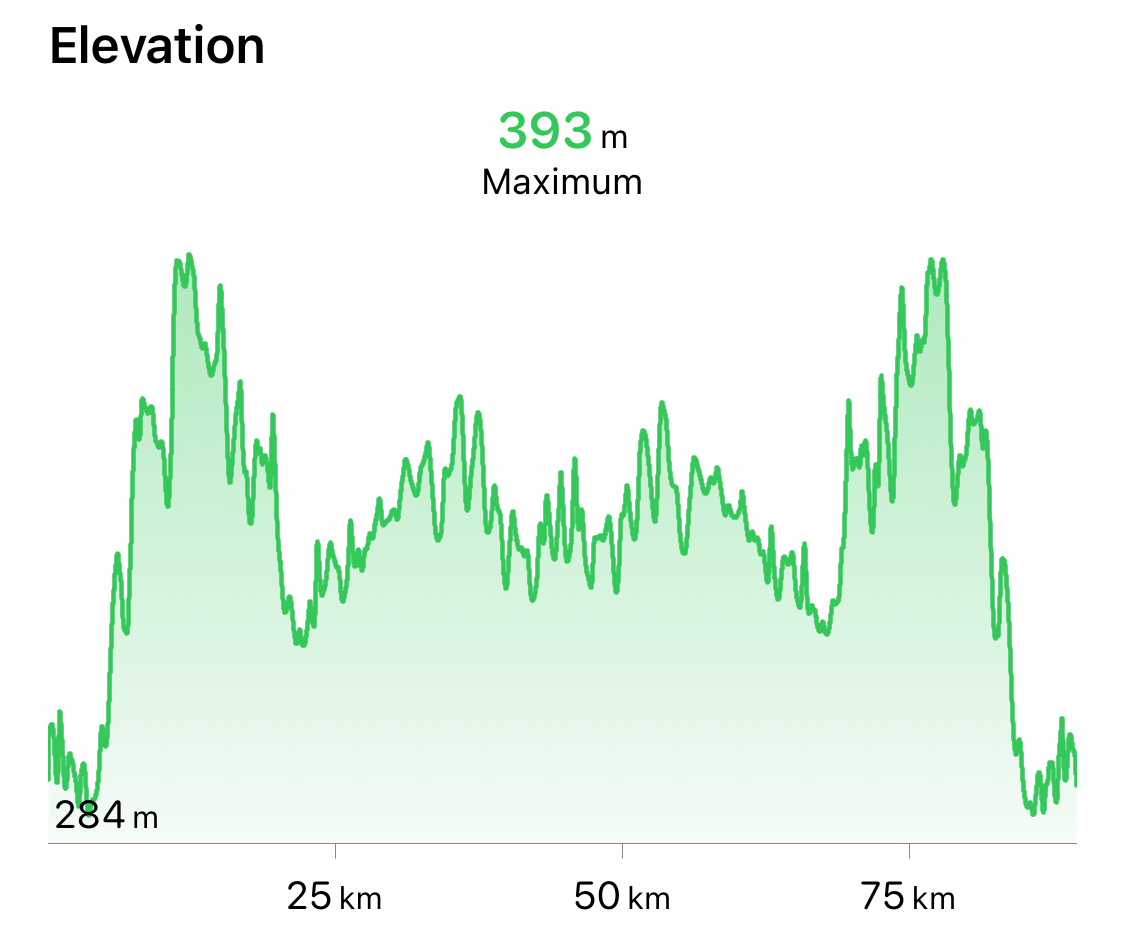
I had a 750mL bottle of electrolytes and 500mL bottle of water on the bike that I consumed throughout, along with a Cliff bar and two energy gels.
The bike course was open to traffic, so we had a few cars to contend with. But, they were very careful and I didn’t see any issues.
Run
T2 was straightforward. I racked my bike, took off my helmet, and switched to running shoes and a hat. One more caffeinated gel and off I went.
My plan was to maintain a 5:30 minutes/km pace for the run with an emphasis on keeping it slow after the bike transition. I immediately had to slow down even more though, as the course starts off with a really steep uphill.
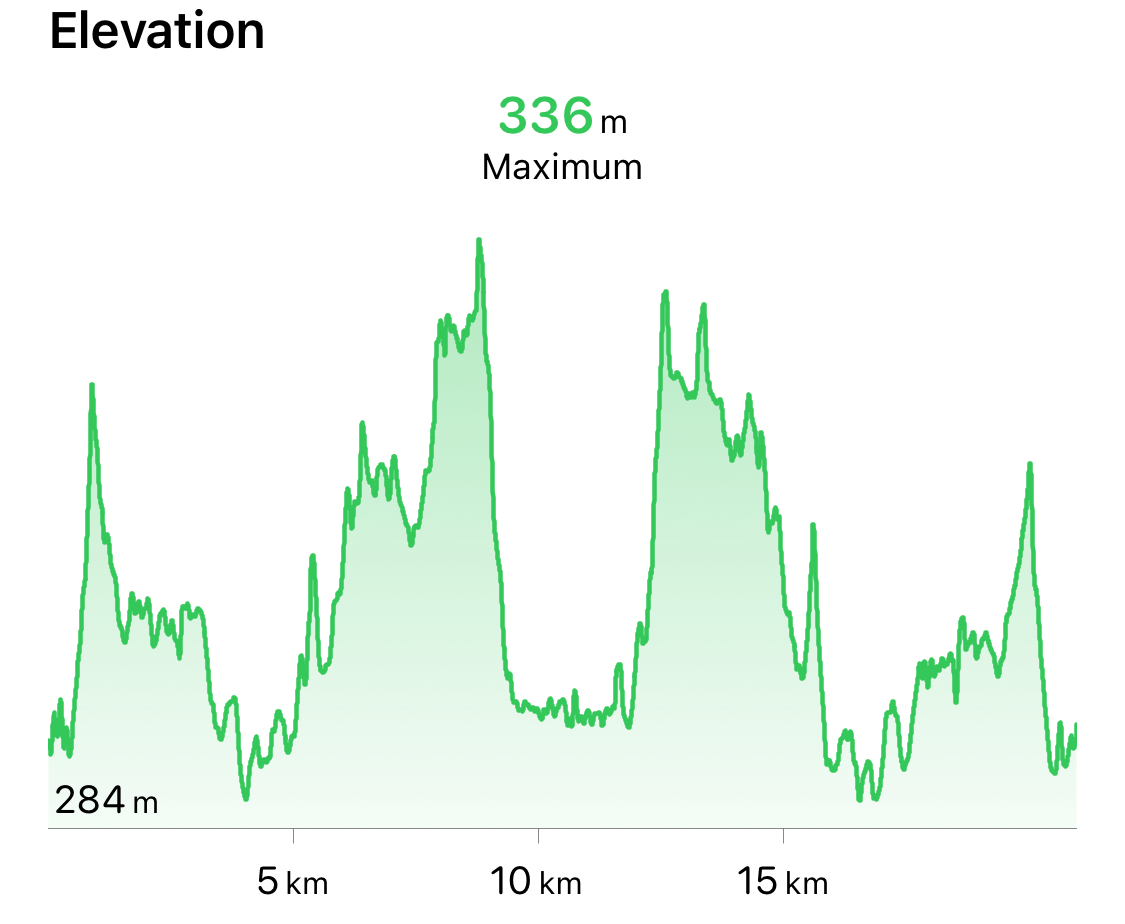
This was followed by a steady uphill from about km 5 to 10 with a big downhill and then back up again on one very steep hill. I came close to walking on this one, but managed to keep a slow pace all the way up.
In Tremblant, I intentionally walked through each aid station on the run. This time I ran through each with one water doused onto my head and one Gatorade to drink.
I’d planned for two gels on the run: the first around km 8 and second around km 14. Somehow I managed to loose one though. As a result, I came very close to hitting the wall on the last 3 km of the run. After a real struggle through km 18, I was able to pull it back together well enough to finish in 1h58m.
Post-race
I’m happy to have improved my time from the Tremblant 70.3. I was in the top third for my age group and top quarter overall. So, well within my top half goal. More importantly though, I was able to enjoy the experience (excluding km 18 of the run).
Just one lesson learned: pack an extra gel or two. They don’t take up much space and the consequences of insufficient fuel are significant.

Simplifying my personal iPhone
Now that I’ve separated my work and personal iPhones, I’m taking some time to simplify my personal device.
The biggest change is that for work, I’m now fully into the Office 365 product. So, email in Outlook, tasks in To Do, and notes in OneNote. Although I really liked using MindNode as my project and task manager and Apple Notes for my notes, I have to admit that this just works so much better for work tasks and with my office Windows PC. This has significantly reduced the demands on my personal phone, which was part of the point.
On the personal side, I’m sticking with Apple Notes and Reminders. These apps have seen lots of improvements recently and are more than sufficient for my needs. I’ve found that sharing notes with my family has been really useful, both as a way to work through family projects and to share reference material.
For music, I’m back to the Apple Music app. I liked the concept and design of the Albums app. I just found that I rarely used it. I am keeping MusicBox as the place to track albums I want to listen to (stuff gets lost in the Recently Added section of the Apple Music app). I’m also tagging albums there for particular moods, since I never seem to be able to remember relevant albums in the moment. MusicBox is a really nice, lightweight companion to Apple Music for these use cases.
For podcasts, I’ve switched back to Apple Podcasts from Overcast. This is really just an experiment with standardizing on stock Apple apps. I don’t expect it to last. Overcast has so many nice refinements and now also has better access to OS integrations that used to favour the Apple Podcasts app.
A couple of things that haven’t changed are getting news via Feedbin in NetNewsWire and journaling in DayOne. Although I’m intrigued by the new Journal app from Apple and will certainly test it out, I expect that I’ll keep my DayOne subscription and the close to 9,000 entries I’ve added.
Knowing my predilections for fiddling with my setup, I’ve intentionally kept my homescreen stable for a couple of years now. No doubt there will be further tweaks once iOS 17 is released. After that, I look forward to another stable setup that I use when necessary and otherwise leave alone.
Milton Sprint Triathlon 🏊♂️🚴♂️🏃♂️
That was fun! Really well organized, friendly racers, and great weather. There were 466 racers, though other than the parking lot, it didn’t seem crowded.

Swim
Mass start by age group for the swim. Temperature was quite nice. Other than an elbow to the nose coming around the last buoy, a pleasant swim 😀.
Bike
The course confronts you almost right away with a steep 320m climb up the escarpment that really tests the legs. After that, some nice rolling hills, until you come back down the escarpment, hanging on for dear life, as you hit about 70 km/hr. Terrifying and exhilarating end to the ride.
Run
Mostly in wooded trails which is nice. Though still has some hills. Since it is only 7K, you can push it, if anything is left in the legs from the bike.
Transitions
These didn’t go very well. I was rather dizzy coming out of the swim and struggled with balance while getting the bike shoes on in T1. This has happened before and is something I should be training for. So, 3:21 on this one.
Then 2:09 at T2 while I fiddled with my shoe laces. I really should have switched these to elastics. Just didn’t get around to it.
Nutrition
I kept is simple: one caffeinated gel at each of the two transitions and a Nuun in the water bottle for my bike.
Apple Watch
This was my first event with the Apple Watch Ultra. Battery life (the main reason I got one) was excellent. I was at about 90% charge the night before, wore it to track sleeping, and then got to the end of race day around 9pm with close to 60% charge.
I also really liked the Triathlon workout in the Multisport category. The automatic transitions worked really well, marking when I started and stopped each component of the race. So, all I had to do was hit the action button at the start of the swim to start the workout tracking and then stop the workout at the end of the run. Everything else worked automatically. Nice to not have to worry about fiddling with the watch at each transition.
☎️ 😱 Living dangerously for seven years with a corporate phone
For seven years now, I’ve been living dangerously by only using my corporate phone for everything. I knew this was wrong, yet couldn’t resist, until this week.
There were only two, day-to-day negative impacts of relying on a corporate phone.
The first, admittedly minor, though surprisingly annoying, one is that any explicit songs in Apple Music were blocked. It isn’t that I feel compelled to listen to explicit lyrics. Rather, there are lots of good songs with a few swear words thrown in, especially for the more high-energy rock I prefer for workouts. Sometimes clean versions are available, though they lack the power of the real versions.
The second, more systematic, one is that iCloud Drive support was blocked. This disabled some important features of many of my favourite apps, like Drafts, Mindnode, Soulver, MusicBox, and Albums. These apps became little islands of inaccessible data that didn’t share with my iPad or Mac, limiting their utility.
Of course the real reason this was a bad idea is exactly what IT says: you shouldn’t mix work with personal. IT has been (appropriately) locking down more and more of the phone, while also adding in VPN and other monitoring apps.
So, why did I do it? Two main reasons: I really don’t like carrying extra stuff and I saved the monthly cost of a personal data plan (given Canada’s rates, this is bigger than you might think).
There was no epiphany that led me to finally get a personal phone. Just a steady realization that meant it was time.
I picked up an iPhone 13 mini. I have no need for the latest phone and really appreciate the smaller size of the mini.
I opted for a Freedom Mobile plan and added in the Apple Watch plan (something I couldn’t do with the corporate phone). My biggest surprise so far is how nice it is to have the Apple Watch Ultra connected via cellular and leave the phone behind. The Apple Watch really is quite functional for my needs without the phone.
Better late than never to this. I’m glad to finally have made the right choice and am enjoying better partitioning of work from the rest of my activities.
What I think about when I say goodbye to my beloved dying pet
But it was still deeply upsetting. My eyes started to water just writing about it. The good death of a beloved animal who has led a good life is both sad and OK. The inescapability of mortality means we have to accept it but we don’t have to feel good about it.
Reading this brought back memories of our prior black lab, Ceiligh, and our decision to euthanize her once she was diagnosed with significant and incurable cancer.
In addition to everything described in this essay, two other factors made this a very difficult decision:
We valued Ceiligh’s role in our family and welcomed her predecesor, Lucy, knowing that the choice might arise again, while also knowing how much she would enrich our lives.

Reading more books in 2022 📚
I read many more books this year than in recent, past years. Although this was intentional, I’m glad it worked out. I really cut back on my various internet feeds, so that I was less distracted away from books. Purchasing a Kobo and connecting it to the local public library was also helpful.
The most influential non-fiction book for me this year was Four Thousand Weeks by Oliver Burkeman. Plenty of practical and insightful advice in this book.
Picking a favourite fiction book is always fraught. This year, I think it was A Closed and Common Orbit by Becky Chambers. Something about the emotional core of this book really resonated with me.
Here’s the full list of books from the year:







































Computation with marbles 🧮🧐
I’ve been interested for a while now in better understanding the underlying mechanics of computers. I’ve also been keen to do something other than stare at a screen. Turing Tumble is a fun solution to both of these goals.
Turing Tumble is an educational game in which you build a mechanical computer that is powered by marbles. The game comes with a comic book that guides you through ever more complex computing principles, adding more sophisticated parts as you progress. Each principle is presented as a challenge in which you’re given a goal and a few starting pieces. You then have to integrate some earlier principles into the new goal to come up with a solution. The challenges get pretty tough! But, I’m enjoying figuring out each puzzle while making progress through the story.
Just as an example, here’s Challenge 26 in which the goal is to release 4 blue marbles, 1 red, and then another 4 blue. The blue, arrow-shaped pieces are bits that allow you to count, while the black piece near the top right corner is an interceptor for stopping computation (warning, spoilers ahead!).
Although the primary audience for this is kids, I’m finding it both fun and educational!
How much does a Triathlon cost? 🏊♂️ 🚴♂️ 🏃♂️💰
Other than knowing if I was physically capable of finishing, the main source of uncertainty when I signed up for my first triathlon was how much it would cost. Starting out, I had one pair of running shoes and some goggles from my kids' swimming lessons. So, I knew I’d need to invest in a lot of gear.
Here’s the list of what I ended up buying along with some commentary. Of course it is important to note that these costs can vary widely, based on what you may already have and the budget you’re willing to spend. For several of these items, there’s a very wide range of costs from barely good enough to really fancy. I tended towards the medium-low end of the distribution: enough to get good, reliable equipment, but far away from top end. I figured I should at least finish one triathlon before investing too much money in equipment.
All amounts are in Canadian dollars and rounded to something reasonable.
Swimming
Total: $800
Biking
Total: $5,600 (yikes)
Running
Total: $400
Other
Some odds and ends:
Total: $3,400
In the end, about $10,000! Seems like a lot (and it is), though it was spread out over 8 months. Plus, this was essentially my only hobby and leisure activity for that time. Nonetheless, I’m grateful to my family for putting up with this.
