Skipping past the unnecessarily dramatic title, The Broken Algorithm That Poisoned American Transportation does make some useful points. As seems typical though these days, the good points are likely not the ones a quick reader would take away. My guess is most people see the headline and think that transportation demand models (TDMs) are inherently broken. Despite my biases, I don’t think this is actually true.
For me, the most important point is about a third of the way through:
nearly everyone agreed the biggest question is not whether the models can yield better results, but why we rely on them so much in the first place. At the heart of the matter is not a debate about TDMs or modeling in general, but the process for how we decide what our cities should look like.
Models are just a tool for helping guide decisions. Ideally we would use them to compare alternatives and pick a favoured “vector” of change (rough direction and magnitude). Then with continuous monitoring and refinements throughout the project’s lifecycle, we can guide decisions towards favoured outcomes. This is why scenario planning, sensitivity tests, and clear presentation of uncertainty are so important. This point is emphasized later in the article:
civil engineers doing the modeling tend to downplay the relevance of the precise numbers and speak more broadly about trends over time. Ideally, they argue, policymakers would run the model with varying population forecasts, land use patterns, and employment scenarios to get a range of expectations. Then, they would consider what range of those expectations the project actually works for.
Although I’m not a civil engineer, this sounds right to me! I get that people want certainty and precise numbers, I just don’t think anyone can provide these things. Major infrastructure projects have inherent risks and uncertainty. We need to acknowledge this and use judgement, along with a willingness to adjust over time. There is no magical crystal ball that can substitute for deliberation. [Me working from home:🧙♂️🔮]
Fortunately for the modellers among us, the article does acknowledge that we’re getting better:
As problematic as they have been, the models have gotten smarter. Especially in the last decade or so, more states are working from dynamic travel models that more closely reflect how humans actually behave. They are better at taking into consideration alternate modes of transportation like biking, walking, and public transportation. And, unlike previous versions, they’re able to model how widening one section of road might create bottlenecks in a different section.
But, wait:
Still, experts warn that unless we change the entire decision-making process behind these projects, a better model won’t accomplish anything. The models are typically not even run—and the results presented to the public—until after a state department of transportation has all but settled on a preferred project.
😔 Maybe it wasn’t the model’s fault after all.
This brings as back to the earlier point: we should be favouring more sophisticated decision-making processes, not just more sophisticated models.
I haven’t yet adopted the minimalist style of my iPhone for my iPad. Rather, I’ve found that setting up “task oriented” Shortcuts on my home screen is a good alternative to arranging lots of app icons.
The one I use the most is a “Reading” Shortcut, since this is my dominant use of the iPad. Nothing particularly fancy. Just a list of potential reading sources and each one starts up a Timery timer, since I like to track how much time I’m reading.
A nice feature of using a Shortcut for this is that I can add other actions, such as turning on Do Not Disturb or starting a specific playlist. I can also add and subtract reading sources over time, depending on my current habits. For example, the first one was Libby for a while, since I was reading lots of library books.
This is another example of how relatively simple Shortcuts can really help optimize how you use your iOS devices.
I’ve been keeping a “director’s commentary” of my experiences in Day One since August 2, 2012 (5,882 entries and counting). I’ve found this incredibly helpful and really enjoy the “On This Day” feature that shows all of my past entries on a particular day.
For the past few months, I’ve added in a routine based on the “5 minute PM” template which prompts me to add three things that happened that day and one thing I could have done to make the day better. This is a great point of reflection and will build up a nice library of what I’ve been doing over time.
My days seem like such a whirlwind sometimes that I actually have trouble remembering what I did that day. So, my new habit is to scroll through my Today view in Agenda. This shows me all of my notes from the day’s meetings. I’ve also created a Shortcut that creates a new note in Agenda with all of my completed tasks from Reminders. This is a useful reminder of any non-meeting based things I’ve done (not everything is a meeting, yet).
I’m finding this new routine to be a very helpful part of my daily shutdown routine: I often identify the most important thing to do tomorrow by reviewing what I did today. And starting tomorrow off with my top priority already identified really helps get the day going quickly.
watchOS 7 has some interesting new features for enhancing and sharing watch faces. After an initial explosion of developing many special purpose watch faces, I’ve settled on two: one for work and another for home.
Both watch faces use the Modular design with the date on the top left, time on the top right, and Messages on the bottom right. I like keeping the faces mostly the same for consistency and muscle memory.
My work watch face than adds the Fantastical complication right in the centre, since I often need to know which meeting I’m about to be late for. Reminders is on the bottom left and Mail in the bottom centre. I have this face set to white to not cause too much distraction.
My home watch face swaps in Now Playing in the centre, since I’m often listening to music or podcasts. And I have Activity in the bottom centre. This face is in orange, mostly to distinguish it from the work watch face.
Surprisingly, I’ve found this distinction between a work and home watch face even more important in quarantine. Switching from one face to another really helps enforce the transition between work and non-work when everything is all done at home.
The watch face that I’d really like to use is the Siri watch face. This one is supposed to intelligently expose information based on my habits. Sounds great, but almost never actually works.
Our predictions for the 2019 Federal race in Toronto were generated by our agent-based model that uses demographic characteristics and results from previous elections. Now that the final results are available, we can see how our predictions performed at the Electoral District level.
For this analysis, we restrict the comparison to just the major parties, as they were the only parties for which we estimated vote share. We also only compare the actual results to the predictions of our base scenario. In the future, our work will focus much more on scenario planning to explain political campaigns.
We start by plotting the difference between the actual votes and the predicted votes at the party and district level.
Distribution of the difference between the predicted and actual proportion of votes for all parties
The mean absolute value of differences from the actual results is 5.3%. In addition, the median value of the differences is 1.28%, which means that we slightly overestimated support for parties. However, as the histogram shows, there is significant variation in this difference across districts. Our highest overestimation was 15.6% and lowest underestimation was -18.5%.
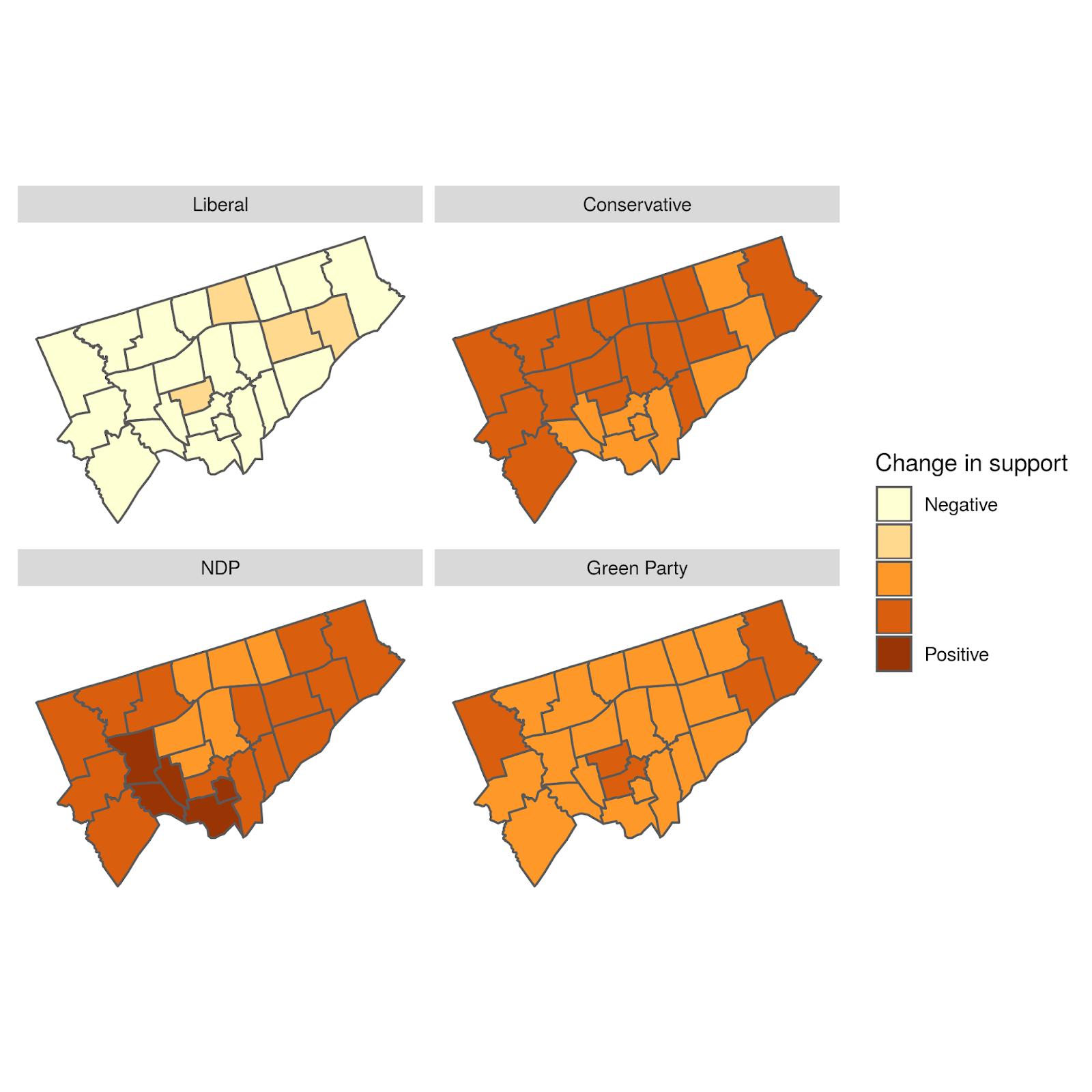
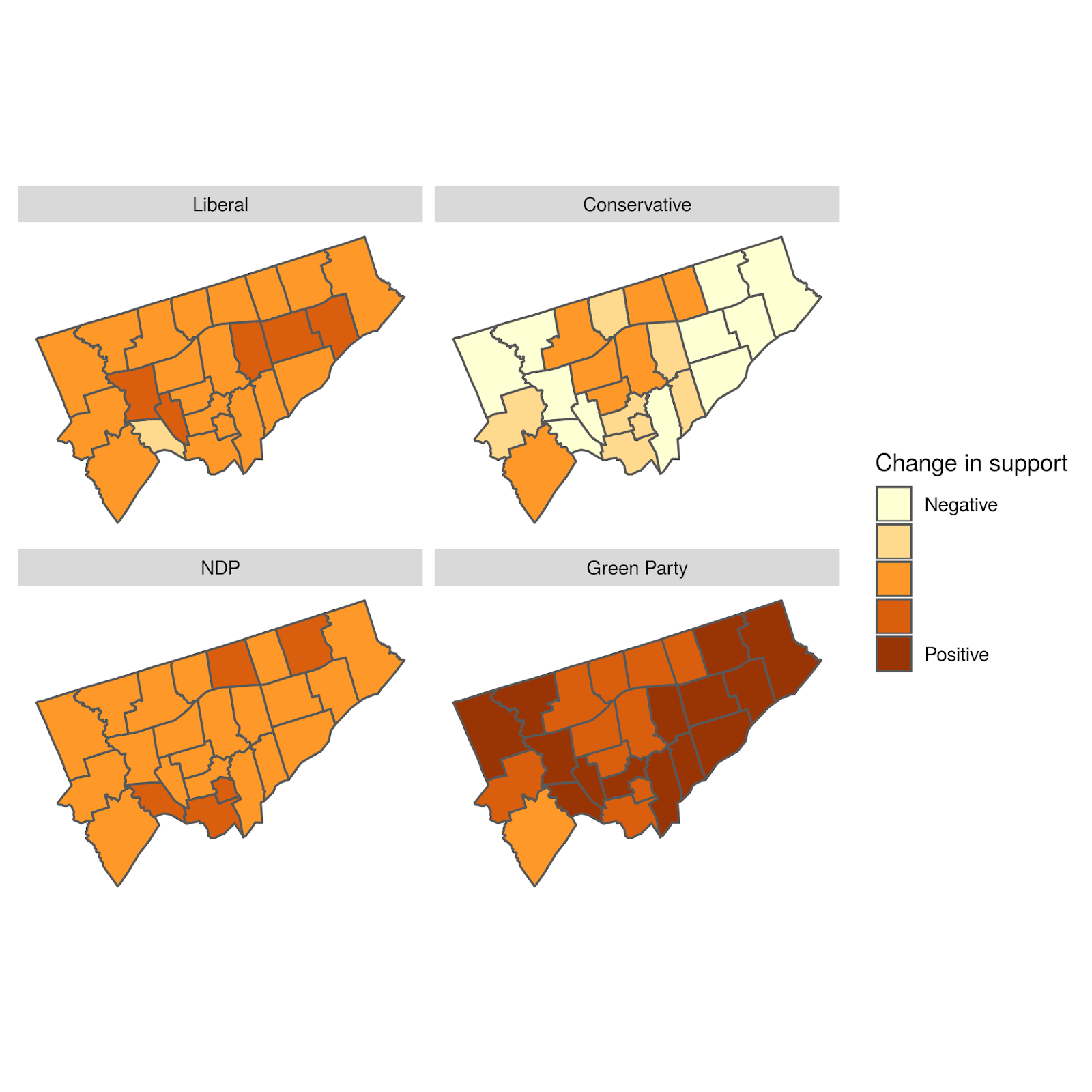
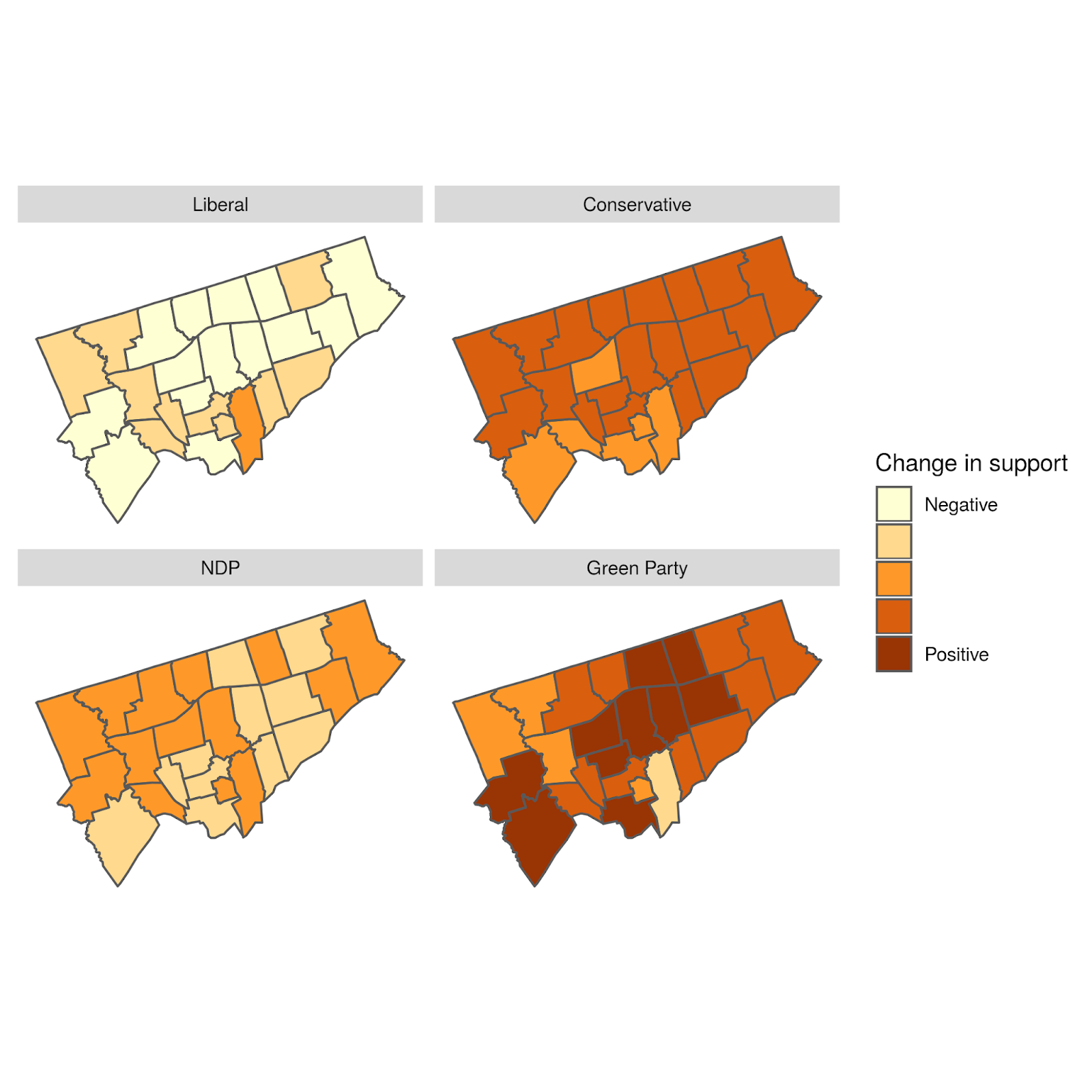
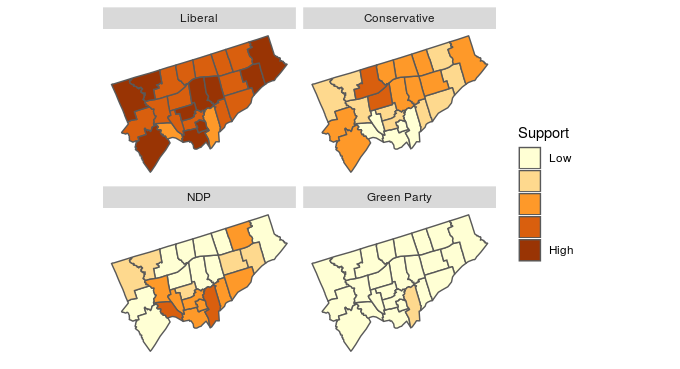
To better understand this variation, we can look at a plot of the geographical distribution of the differences. In this figure, we show each party separately to illuminate the geographical structure of the differences.
Geographical distribution of the difference between the predicted and actual proportion of votes by Electoral District and party
The overall distribution of differences doesn’t have a clear geographical bias. In some sense, this is good, as it shows our agent-based model isn’t systematically biased to any particular Electoral District.
However, our model does appear to generally overestimate NDP support while underestimating Liberal support. These slight biases are important indicators for us in recalibrating the model.
Overall, we’re very happy with an error distribution of around 5%. As described earlier, our primary objective is to explain political campaigns. Having accurate predictions is useful to this objective, but isn’t the primary concern. Rather, we’re much more interested in using the model that we’ve built for exploring different scenarios and helping to design political campaigns.
I’m neither an epidemiologist nor a medical doctor. So, no one wants to see my amateur disease modelling.
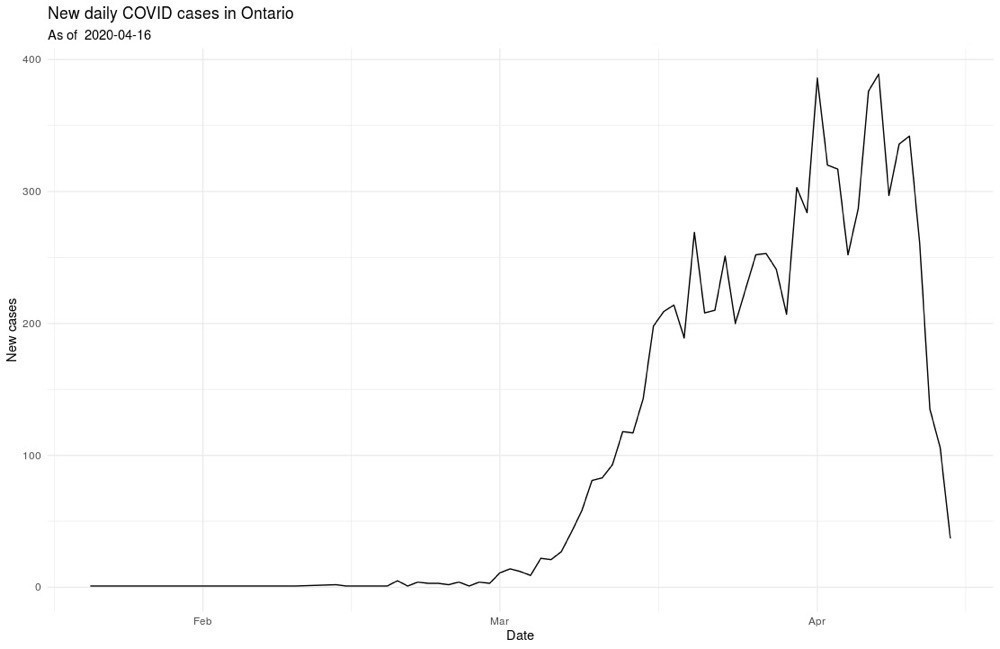
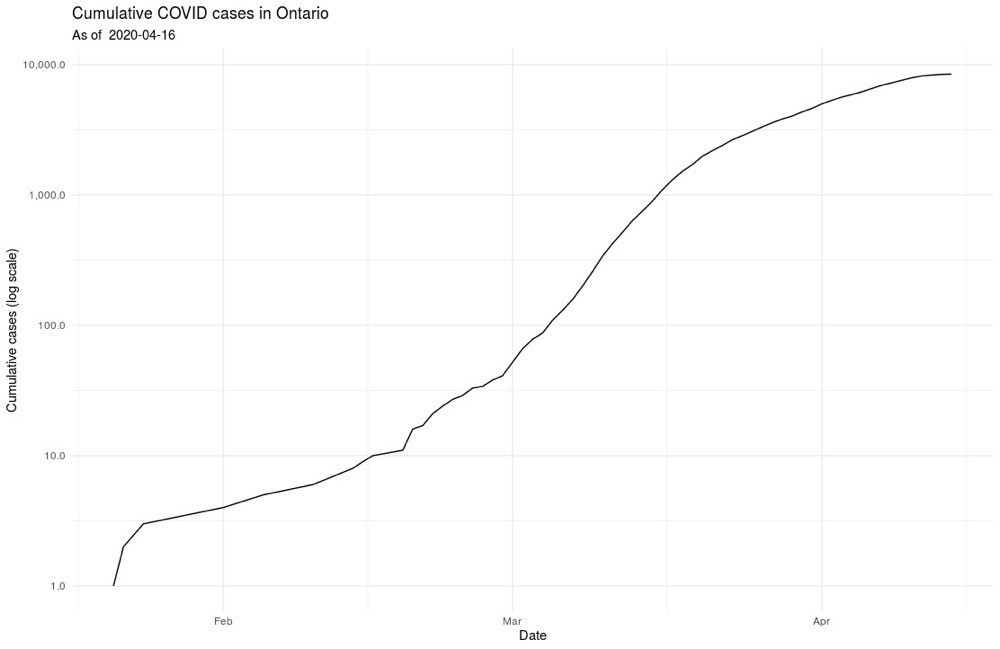
That said, I’ve complained in the past about Ontario’s open data practices. So, I was very impressed with the usefulness of the data the Province is providing for COVID: a straightforward csv file that is regularly updated from a stable URL.
Using the data is easy. Here’s an example of creating a table of daily counts and cumulative totals:
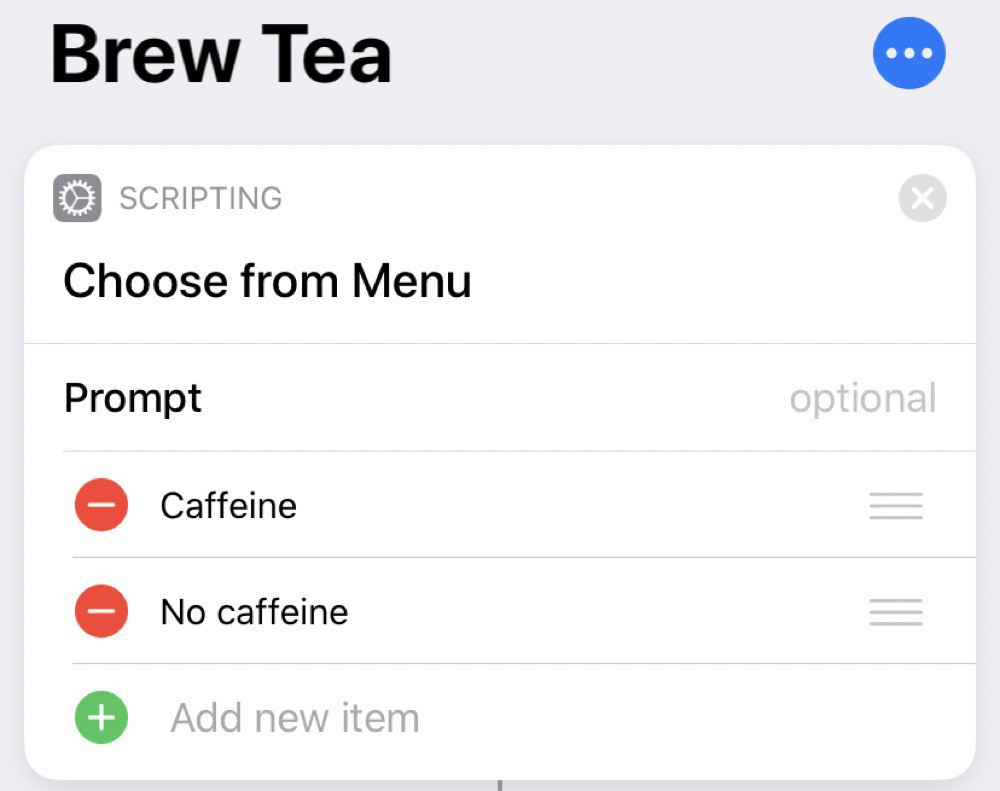
Since I’m mostly stuck inside these days, I find I’m drinking more tea than usual. So, as a modification of my brew coffee shortcut, I’ve created a brew tea shortcut.
This one is slightly more complicated, since I want to do different things depending on if the tea is caffeinated or not.
We start by making this choice:
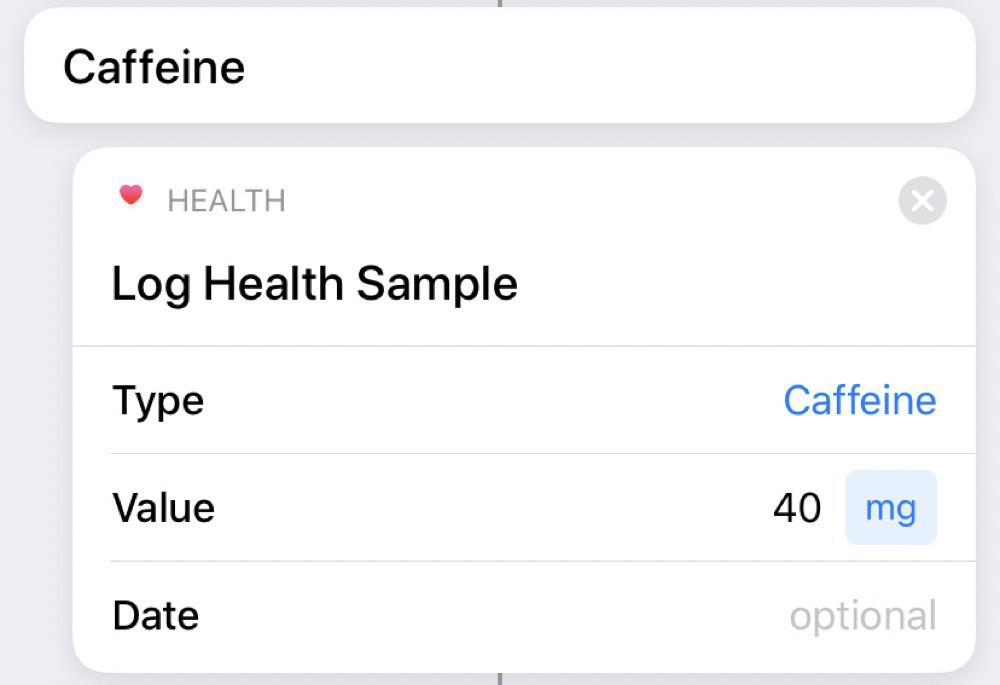
Then, if we choose caffeine, we log this to the Health app:
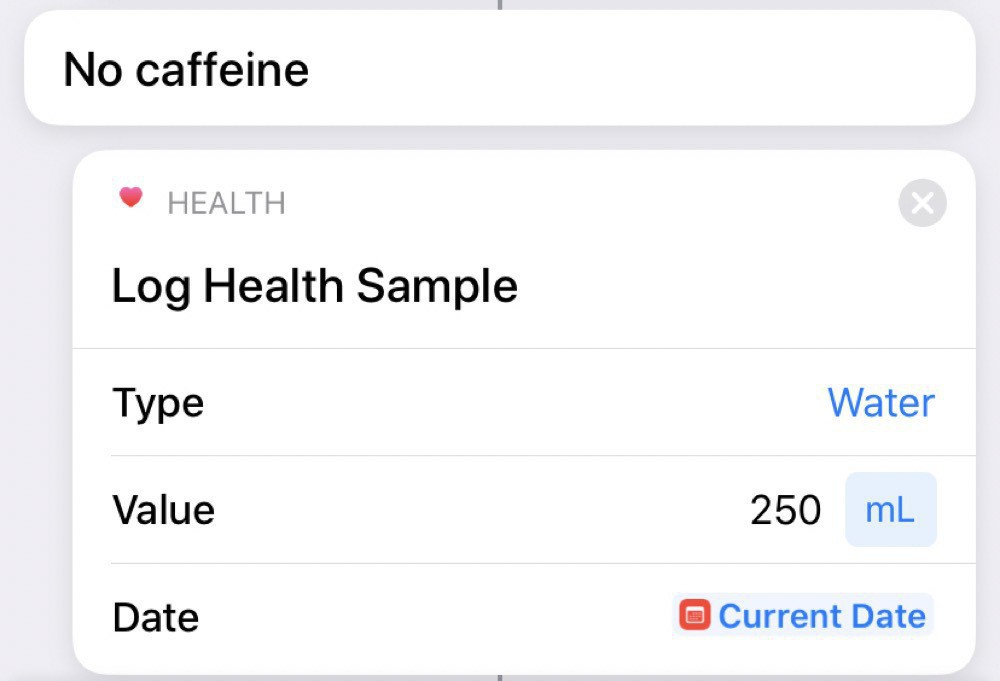
Uncaffeinated tea counts as water (at least for me):
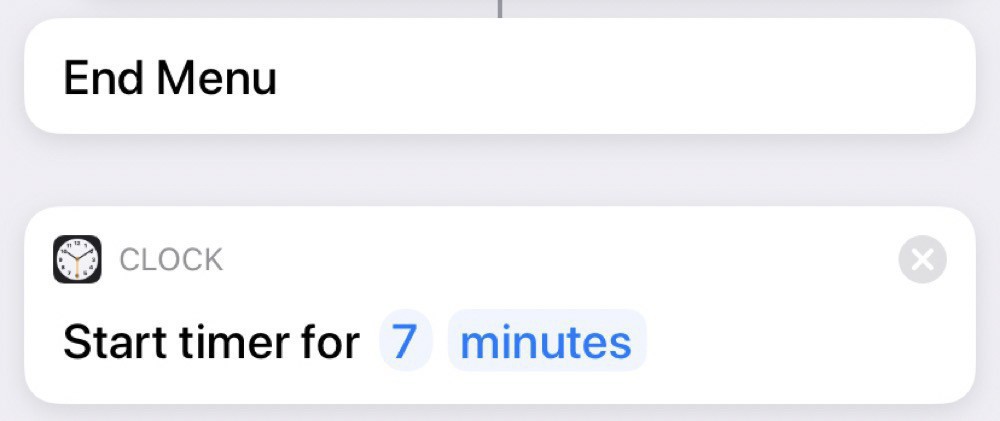
And, then, regardless of the type of tea, we set a timer for 7 minutes:
Running this one requires more interactions with Siri, since she’ll ask which type we want. We can either reply by voice or by pressing the option we want on the screen.
I’ve been tracking my time at work for a while now, with the help of Toggl and Timery. Now that I’m working from home, work and home life are blending together, making it even more useful to track what I’m doing.
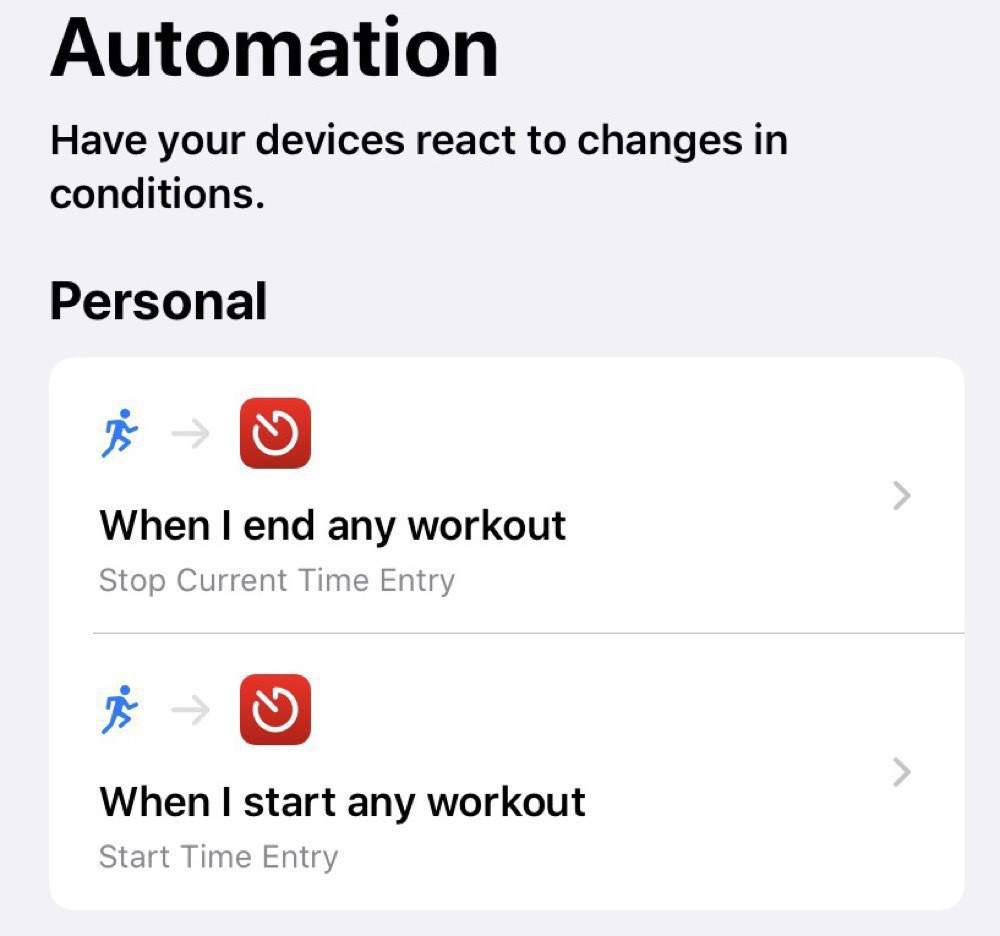
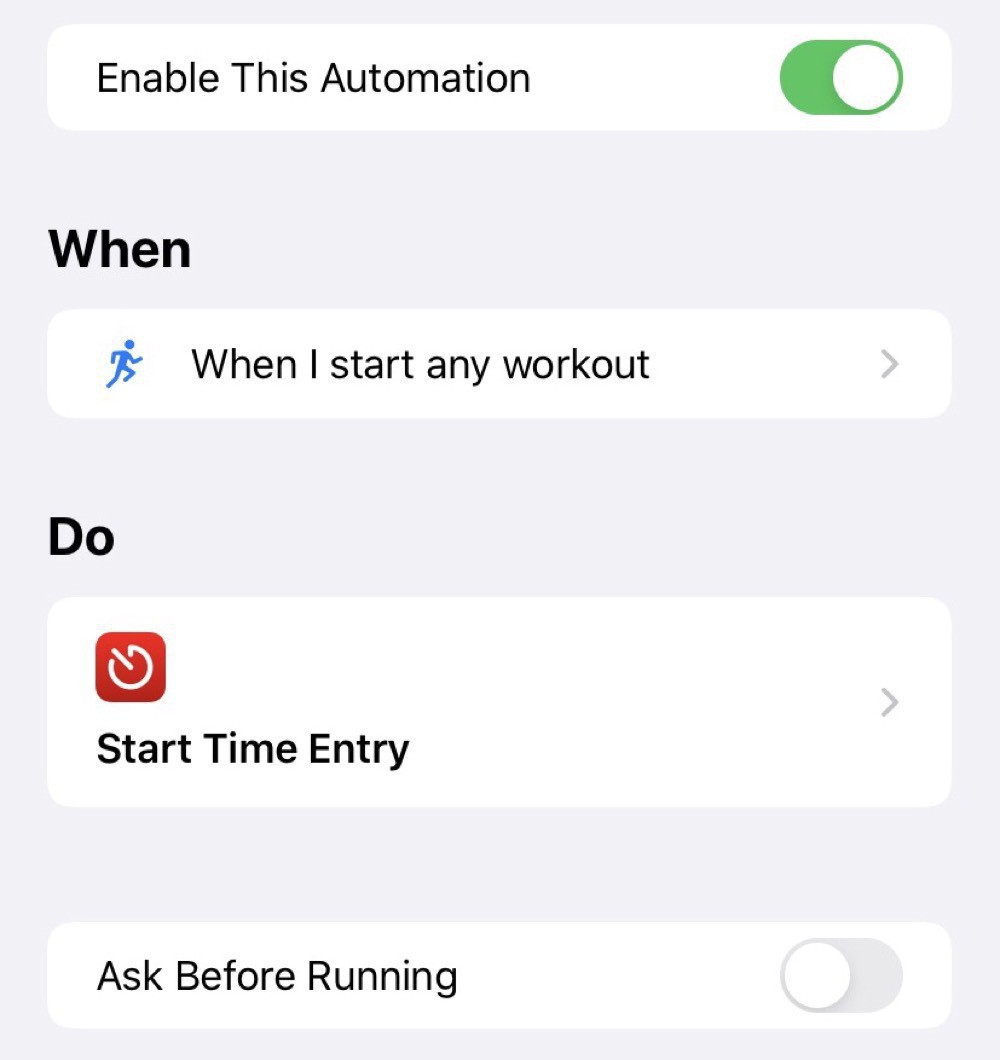
Physical exercise is essential to my sanity. So, I wanted to integrate my Apple Watch workouts into my time tracking. I thought I’d be able to leverage integration with the Health app through Shortcuts to add in workout times. Turns out you can’t access this kind of information and I had to take a more indirect route using the Automation features in Shortcuts.
I’ve setup two automations: one for when I start an Apple Watch workout and the other for when I stop the workout:
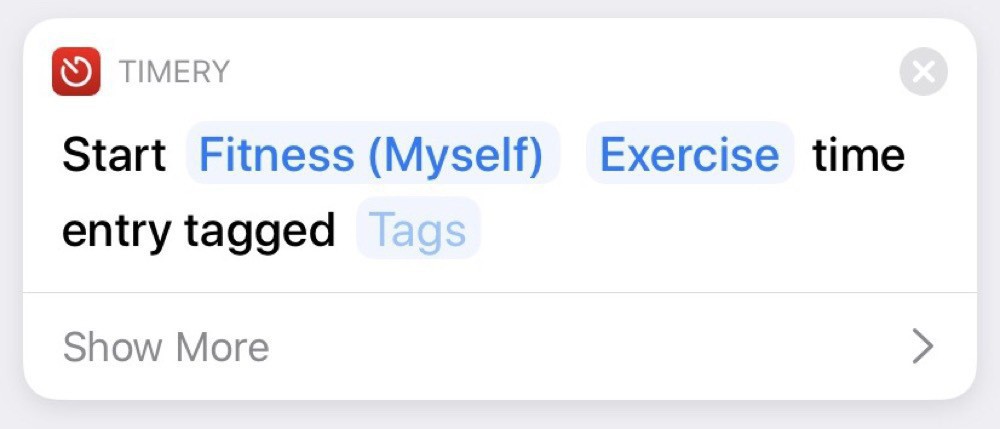
The starting automation just starts an entry in Timery:
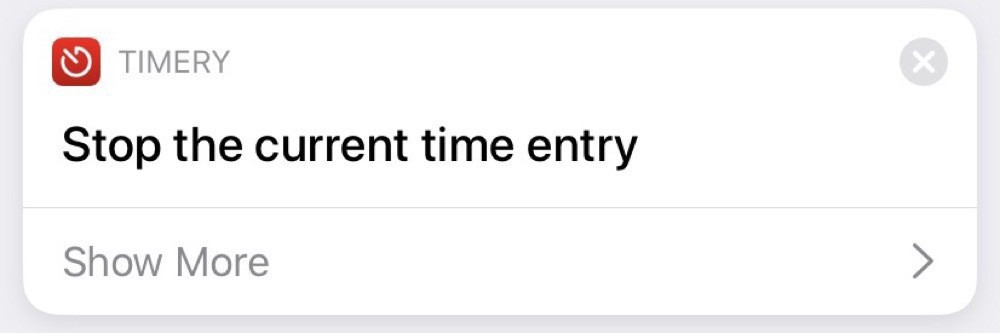
The stopping automation, unsurprisingly, stops the running entry:
As with most of my Shortcuts, this is a simple one. Developing a portfolio of these simple automations is really helpful for optimizing my processes and freeing up time for my priorities.
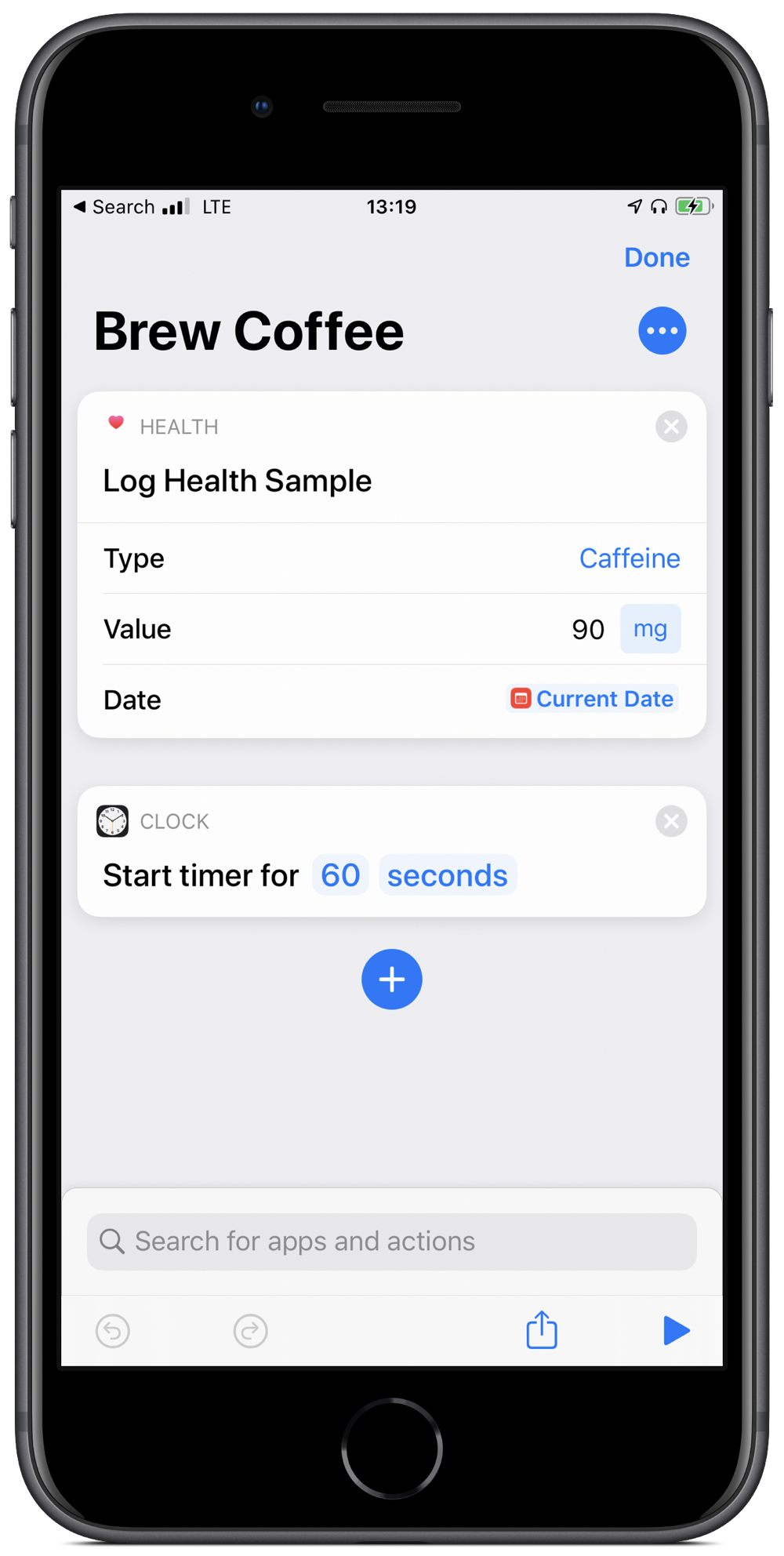
That said, it is often the smaller automations that add up over time to make a big difference. My most used one is also the simplest in my Shortcuts Library. I use it every morning when I make my coffee. All the shortcut does is set a timer for 60 seconds (my chosen brew time for the Aeropress) and logs 90mg of caffeine into the Health app.
All I need to do is groggily say “Hey Siri, brew coffee” and then patiently wait for a minute. Well, that plus boil the water and grind the beans.
Simple, right? But that’s the point. Even simple tasks can be automated and yield consistencies and productivity gains.
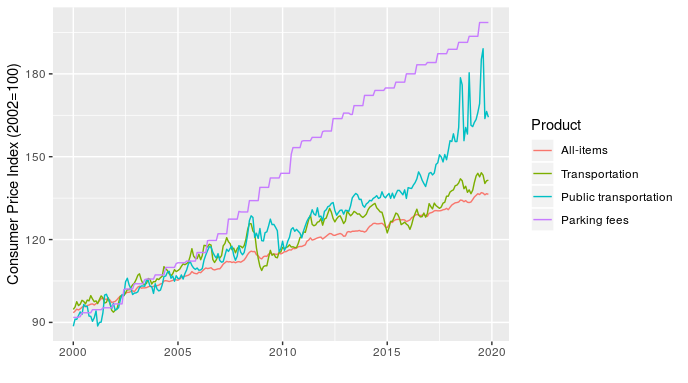
I’m delivering a seminar on estimating capital costs for large transit projects soon. One of the main concepts that seems to confuse people is inflation (including the non-intuitive terms nominal and real costs). To guide this discussion, I’ve pulled data from Statistics Canada on the Consumer Price Index (CPI) to make a few points.
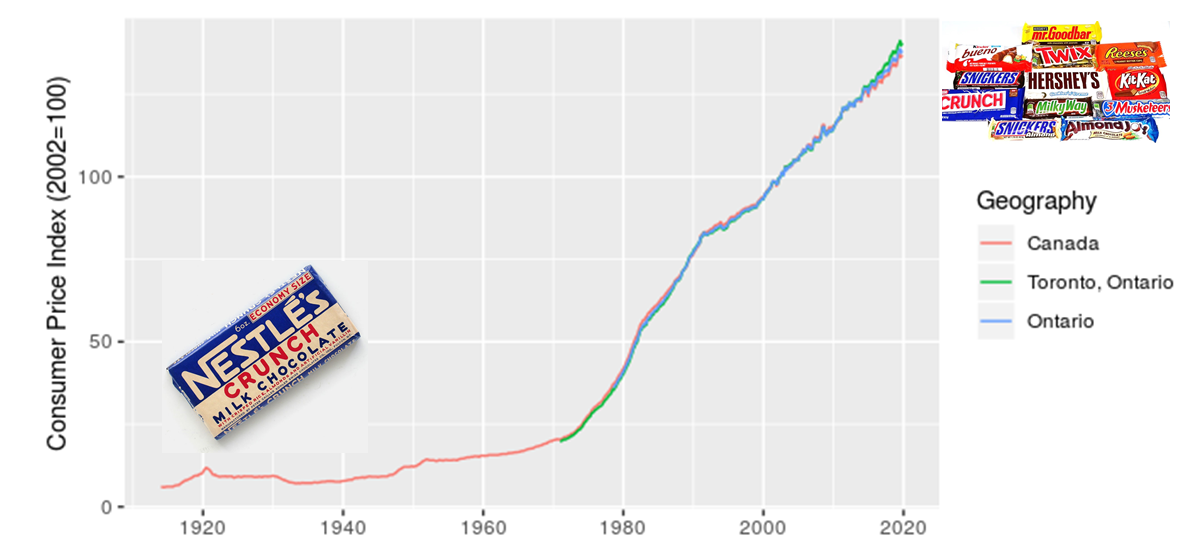
The first point is that, yes, things do cost more than they used to, since prices have consistently increased year over year (this is the whole point of monetary policy). I’m illustrating this with a long-term plot of CPI in Canada from 1914-01-01 to 2019-11-01.
I added in the images of candy bars to acknowledge my grandmother’s observation that, when she was a kid, candy only cost a penny. I also want to make a point that although costs have increased, we also now have a much greater diversity of candy to choose from. There’s an important analogy here for estimating the costs of projects, particulary those with a significant portion of machinery or technology assets.
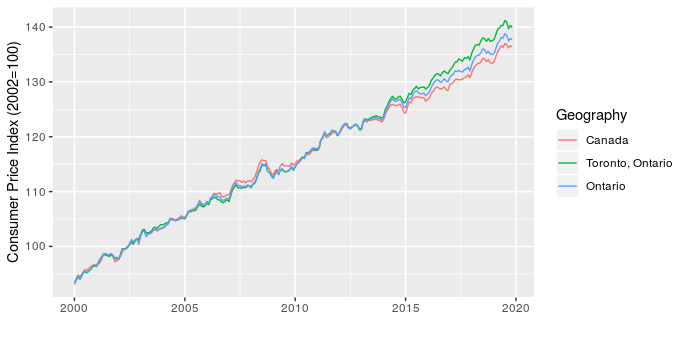
The next point I want to make is that location matters, which I illustrate with a zoomed in look at CPI for Canada, Ontario, and Toronto.
This shows that over the last five years Toronto has seen higher price increases than the rest of the province and country. This has implications for project costing, since we may need to consider the source of materials and location of the project to choose the most appropriate CPI adjustment.
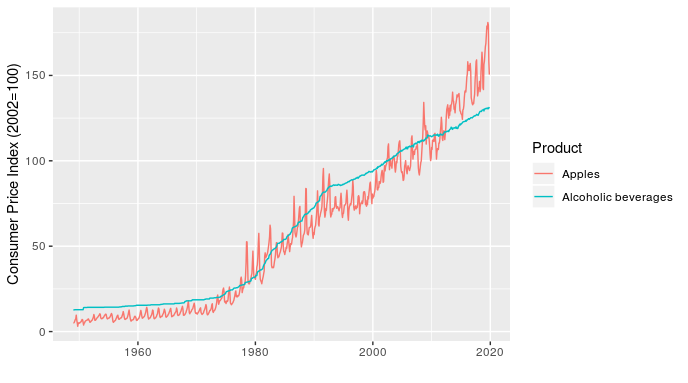
The last point I want to make is that the type of product also matters. To start, I illustrate this by comparing CPI for apples and alcoholic beverages (why not, there are 330 product types in the data and I have to pick a couple of examples to start).
In addition to showing how relative price inflation between products can change over time (the line for apples crosses the one for alcoholic beverages several times), this chart shows how short-term fluctuations in price can also differ. For example, the line for apples fluctuates dramatically within a year (these are monthly values), while alcoholic beverages is very smooth over time.
Once I’ve made the point with a simple example, I can then follow up with something more relevant to transit planners by showing how the price of transportation, public transportation, and parking have all changed over time, relative to each other and all-items (the standard indicator).
At least half of transit planning seems to actually be about parking, so that parking fees line is particularly relevant.
Making these charts is pretty straightforward, the only real challenge is that the data file is large and unwieldy. The code I used is here.
Podcasts are great. I really enjoy being able to pick and choose interesting conversations from such a broad swath of topics. Somewhere along the way though, I managed to subscribe to way more than I could ever listen to and the unlistened count was inducing anxiety (I know, a real first world problem).
So, time to start all over again and only subscribe to a chosen few:
Quirks & Quarks is the one I’ve been subscribed to the longest and is a reliable overview of interesting science stories. I’ve been listening to this one for so long that I used to rely on an AppleScript to get episodes into my original scroll wheel iPod, well before podcasts were embraced by Apple.
In Our Time is another veteran on my list. I really like the three-academics format and Melvyn Bragg is a great moderator. This show has a fascinating diversity of topics in science, history, and literature.
All Songs Considered has helped me keep up with the latest music and Bob Boilen is a very good interviewer.
The Talk Show has kept me up to date on the latest in Apple and related news since at least 2007.
Exponent has really helped me think more clearly about strategy with discussions of tech and society.
Focused has been a very helpful biweekly reminder to think more carefully about what I’m working on and how to optimize my systems.
Making Sense has had reliably interesting discussions from Sam Harris. It just recently went behind a paywall. But I’m happy to pay for it, which comes with access to the Waking Up app.
I admire what Jesse Brown has built with CANADALAND and happily support it.
Mindscape has had some of the most interesting episodes of any of my subscriptions in the last several months. There’s definitely a bias towards quantum mechanics and physics, but there’s nothing wrong with that.
When all together on a list like this, it looks like a lot. Many are biweekly though, so they don’t accumulate.
I use Overcast for listening to these. I’ve tried many other apps and this one has the right mix of features and simplicity for me. I also appreciate the freedom of the Apple Watch integration which allows me to leave my phone at home and still have podcasts to listen to.
As outlined in our last two posts, our algorithm has “learned” how to simulate the behavioural traits of over 2 million voters in Toronto. This allows us to turn their behavioural “dials” and see what happens.
To demonstrate, we’ll simulate three scenarios:
The “likeability” of the Liberal Party falls by 10% from the baseline (i.e., continues to fall);
The Conservative Party announces a policy stance regarding climate change much more aligned with the other parties; and
People don’t vote strategically and no longer consider the probability of each candidate winning in their riding (i.e., they are free to vote for whomever they align with and like the most, somewhat as if proportional representation were a part of our voting system).
Let’s examine each scenario separately:
1 – If Liberal “likeability” fell
In this scenario, the “likeability” scores for the Liberals in each riding falls by 10% (the amount varies by riding). This could come from a new scandal (or increased salience and impact of previous ones).
What we see in this scenario is a nearly seven point drop in Liberal support across Toronto, about half of which would be picked up by the NDP. This would be particularly felt in certain ridings that are already less aligned on policy where changes in “likeability” have a greater impact. The Libs would only safely hold 13/25 seats, instead of 23/25.
From a seat perspective, the NDP would pick up another seat (for a total of three) in at least 80% of our simulations – namely York South-Weston. (It would also put four – Beaches-East York, Davenport, Spadina-Fort York, and University-Rosedale – into serious play.) Similarly, the Conservatives would pick up two seats in at least 80% of our simulations – namely Eglinton-Lawrence and York Centre (and put Don Valley North, Etobicoke Centre, and Willowdale into serious play).
This is a great example of how changing non-linear systems can produce results that are not linear (meaning they cannot be easily predicted by polls or regressions).
2 – If Conservatives undifferentiated themselves on climate change
In this scenario, the Conservatives announce a change to their policy position on a major issue, specifically climate change. The salience of this change would be immediate (this can also be changed, but for simplicity we won’t do so here). It may seem counterintuitive, but it appears that the Conservatives, by giving up a differentiating factor, would actually lose voters. Specifically, in this scenario, no seats change hands, but the Conservatives actually give up about three points to the Greens.
To work this through, imagine a voter who may like another party more, but chooses to vote Conservative specifically because their positions on climate change align. But if the party moved to align its climate change policy with other parties, that voter may decide that there is no longer a compelling enough reason to vote Conservative. If there are more of these voters than voters the party would pick up by changing this one policy (e.g., because there are enough other policies that still dissuade voters from shifting to the Conservatives), then the Conservatives become worse off.
The intuition may be for the defecting Conservative voters discussed above to go Liberal instead (and some do), but in fact, once policies look more alike, “likeability” can take over, and the Greens do better there than the Liberals.
This is a great example of how the emergent properties of a changing system cannot be seen by other types of models.
Proportional Representations
Recent analysis done by P.J. Fournier (of 338Canada) for Macleans Magazine used 338Canada’s existing poll aggregations to estimate how many seats each party would win across Canada if (at least one form of) proportional representation was in place for the current federal election. It is an interesting thought experiment and allows for a discussion of the value of changing our electoral practice.
As supportive as we are of such analysis, this is an area of analysis perfectly set up for agent-based modeling. That’s because Fournier’s analysis assumes no change in voting behavior (as far as we can tell), whereas ABM can relax that assumption and see how the algorithm evolves.
To do so, we have our voters ignore the winning probabilities of each candidate and simply pick who they would want to (including their “likeability”).
Perhaps surprisingly, the simulations show that the Liberals would lose significant support in Toronto (and likely elsewhere). They would drop to third place, behind the Conservatives (first place) and the Greens (second place).
Toronto would transform into four-party city: depending on the form of proportional representation chosen, the city would have 9-12 Conservative seats, 4-7 Green seats, 2-5 Liberal seats, and 2-3 NDP seats.This suggests that most Liberal voters in Toronto are supportive only to avoid their third or fourth choice from winning. This ties in with the finding that Liberals are not well “liked” (i.e., outside of their policies), and might also suggest why the Liberals back-tracked on electoral reform – though such conjecture is outside our analytical scope. Nonetheless, it does support the idea that the Greens are not taken seriously because voters sense that the Greens are not taken seriously by other voters.
More demonstrations are possible
Overall, these three scenarios showcase how agent-based modeling can be used to see the emergent outcomes of various electoral landscapes. Many more simulations could be run, and we welcome ideas for things that would be interesting to the #cdnpoli community.
In our last post, our analysis assumed that voters had a very good sense of the winning probabilities for each candidate in their ridings. This was probably an unfair assumption to make - voters have a sense of which two parties might be fighting for the seat, but unlikely that they know the z-scores based on good sample size polls.
So, we’ve loosened that statistical knowledge a fair amount, whereby voters only have some sense of who is really in the running in their ridings. While that doesn’t change the importance of “likeability” (still averaging around 50% of each vote), it does change which parties' votes are driven by “likeability” more than their policies.
Now, it is in fact the Liberals who fall to last in “likeability” - and by a fairly large margin - coming last or second last in every riding. This suggests that a lot of people are willing to hold their nose and vote for the Libs.
On average, the other three parties have roughly equal “likeability”, but this is more concentrated for some parties than for others. For example, the Greens appear to be either very well “liked” or not “liked” at all. They are the most “liked” in 13/25 ridings and least “liked” in 9/25 ridings - and have some fairly extreme values for “likeability”. This would suggest that some Green supporters are driven entirely by policy while others are driven by something else.
The NDP and Conservatives are more consistent, but the NDP are most “liked” in 10/25 ridings whereas the Conservatives are most “liked” in the remaining 2/25 ridings.
As mentioned in the last post, we’ll be posting some scenarios soon.
The goal of PsephoAnalytics is to model voting behaviour in order to accurately explain political campaigns. That is, we are not looking to forecast ongoing campaigns – there are plenty of good poll aggregators online that provide such estimation. But if we can quantitatively explain why an ongoing campaign is producing the polls that it is, then we have something unique.
That is why agent-based modeling is so useful to us. Our model – as a proof of concept – can replicate the behaviour of millions of individual voters in Toronto in a parameterized way. Once we match their voting patterns to those suggested by the polls (specifically those from CalculatedPolitics, which provides riding-level estimates), we can compare the various parameters that make up our agents behaviour and say something about them.
We can also, therefore, turn those various behavioural dials and see what happens. For example, what if a party changed its positions on a major policy issue, or if a party leader became more likeable? That allows us to estimate the outcomes of such hypothetical changes without having to invest in conducting a poll.
Investigating the 2019 Federal Election
As in previous elections, we only consider Toronto voters, and specifically (this time) how they are behaving with respect to the 2019 federal election. We have matched the likely voting outcomes of over 2 million individual voters with riding-level estimates of support for four parties: Liberals, Conservatives, NDP, and Greens. This also means that we can estimate the response of voters to individual candidates, not just the parties themselves.
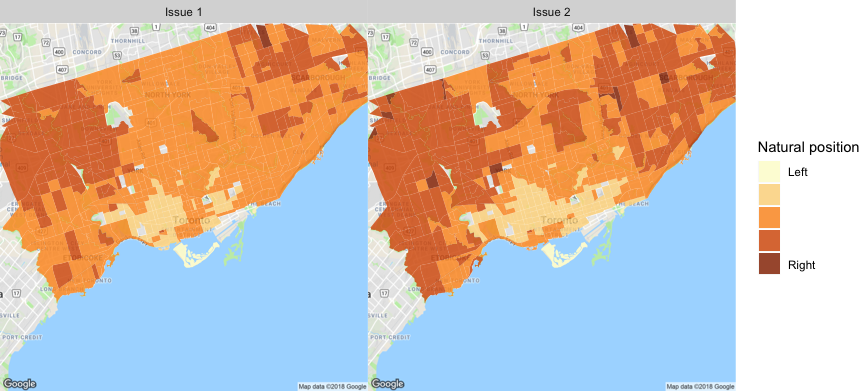
First, let’s start with the basics – here are the likely voter outcomes by ridings for each party, as estimated by CalculatedPolitics on October 16.
As these maps show, the Liberals are expected to win 23 of Toronto’s 25 ridings. The two exceptions are Parkdale-High Park and Toronto-Danforth, which are leaning NDP. Four ridings, namely Eglinton-Lawrence, Etobicoke Centre, Willowdale, and York Centre, see the Liberals slightly edging out the Conservatives. Another four ridings, namely Beaches-East York, Davenport, University-Rosedale, and York South-Weston, see the Liberals slightly edging out the NDP. The Greens do no better than 15% (Toronto Danforth), average about 9% across the city, and are highly correlated with support for the NDP.
What is driving these results? First, a reminder about some of the parameters we employ in our model. All “agents” (e.g., voters, candidates) take policy positions. For voters, these are estimated using numerous historical elections to derive “natural” positions. For candidates, we assign values based on campaign commitments (e.g., from CBC’s coverage, though we could also simply use a VoteCompass). Some voters can also care about policy more than others, meaning they care less about non-policy factors (we use the term “likeability” to capture all these non-policy factors). As such, candidates also have a “likeability” score. Voters also have an “engagement” score that indicates how likely they are to pay attention to the campaign and, more importantly, vote at all. Finally, voters can see polls and determine how likely it is that certain parties will win in their riding. Each voter then determine, for each party a) how closely is their platform aligned with the voter’s issue preferences; b) how much do they “like” the candidate (for non-policy reasons); and c) how likely is it the candidate can win in their riding. That information is used by the voter to score each candidate, and then vote for the candidate with the highest score, if the voter chooses to vote at all. (There are other parameters used, but these few provide much of the differentiation we see.)
Based on this, there are a couple of key take-aways from the 2019 federal election:
“Likeability” is important, with about 50% of each vote, on average, being determined by how much the voter likes the party. The importance of “likeability” ranges from voter to voter (extremes of 11% and 89%), but half of voters use “likeability” to determine somewhere between 42% and 58% of their vote.
Given that, some candidates are simply not likeable enough to overcome a) their party platforms; or b) their perceived unlikelihood of victory (over which they have almost no control). For example, the NDP have the highest average “likeability” scores, and rank first in 18 out of 25 ridings. By contrast, the Greens has the lowest average. This means that policy issues (e.g., climate change) are disproportionately driving Green Party support, whereas something else (e.g., Jagmeet Singh’s popularity) is driving NDP support.
In our next post, we’ll look at some scenarios where we change some of these parameters (or perhaps more drastic things).
For several years now, I’ve been a very happy Things user for all of my task management. However, recent reflections on the nature of my work have led to some changes. My role now mostly entails tracking a portfolio of projects and making sure that my team has the right resources and clarity of purpose required to deliver them. This means that I’m much less involved in daily project management and have a much shorter task list than in the past. Plus, the vast majority of my time in the office is spent in meetings to coordinate with other teams and identify new projects.
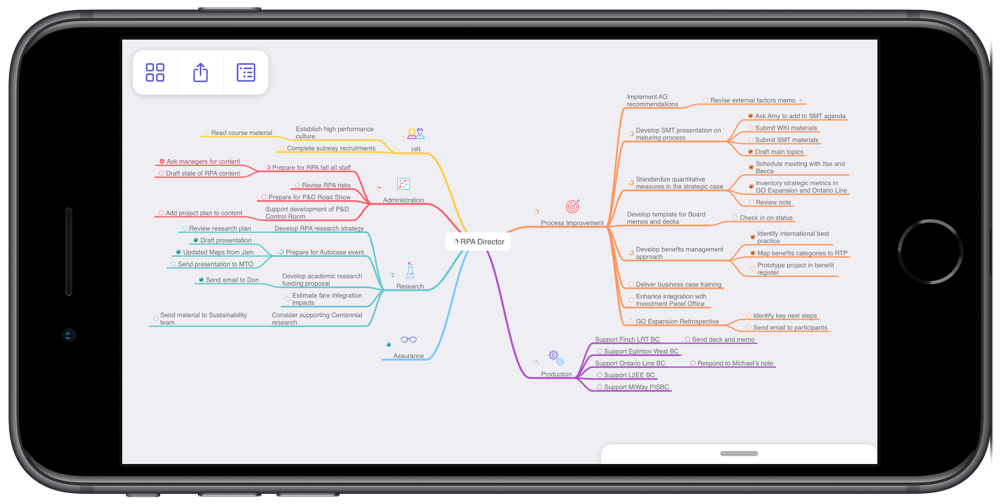
As a result, in order to optimize my systems, I’ve switched to using a combination of MindNode and Agenda for my task managment.
MindNode is an excellent app for mind mapping. I’ve created a mind map that contains all of my work-related projects across my areas of focus. I find this perspective on my projects really helpful when conducting a weekly review, especially since it gives me a quick sense of how well my projects are balanced across areas. As an example, the screenshot below of my mind map makes it very clear that I’m currently very active with Process Improvement, while not at all engaged in Assurance. I know that this is okay for now, but certainly want to keep an eye on this imbalance over time. I also find the visual presentation really helpful for seeing connections across projects.
MindNode has many great features that make creating and maintaining mind maps really easy. They look good too, which helps when you spend lots of time looking at them.
Agenda is a time-based note taking app. MacStories has done a thorough series of reviews, so I won’t describe the app in any detail here. There is a bit of a learning curve to get used to the idea of a time-based note, though it fits in really well to my meeting-dominated days and I’ve really enjoyed using it.
One point to make about both apps is that they are integrated with the new iOS Reminders system. The new Reminders is dramatically better than the old one and I’ve found it really powerful to have other apps leverage Reminders as a shared task database. I’ve also found it to be more than sufficient for the residual tasks that I need to track that aren’t in MindNode or Agenda.
I implemented this new approach a month ago and have stuck with it. This is at least three weeks longer than any previous attempt to move away from Things. So, the experiment has been a success. If my circumstances change, I’ll happily return to Things. For now, this new approach has worked out very well.
RStudio Cloud is a great service that provides a feature-complete version of RStudio in a web browser. In previous versions of Safari on iPad, RStudio Cloud was close to unusable, since the keyboard shortcuts didn’t work and they’re essential for using RStudio. In iPadOS, all of the shortcuts work as expected and RStudio Cloud is completely functional.
Although most of my analytical work will still be on my desktop, having RStudio on my iPad adds a very convenient option. RStudio Cloud also allows you to setup a project with an environment that persists across any device. So, now I can do most of my work at home, then fix a few issues at work, and refine at a coffee shop. Three different devices all using the exact same RStudio project.
One complexity with an RStudio Cloud setup is GitHub access. The usual approach of putting your git credentials in an .REnviron file (or equivalent) is a bad idea on a web service like RStudio Cloud. So, you need to type your git credentials into the console. To avoid having to do this very frequently, follow this advice and type this into the console:
My goal for the home screen is to stay focused on action by making it easy to quickly capture my intentions and to minimize distractions. With previous setups I often found that I’d unlock the phone, be confronted by a screen full of apps with notification badges, and promptly forget what I had intended to do. So, I’ve reduced my home screen to just two apps.
Drafts is on the right and is likely my most frequently used app. As the tag line for the app says, this is where text starts. Rather than searching for a specific app, launching it, and then typing, Drafts always opens up to a blank text field. Then I type whatever is on my mind and send it from Drafts to the appropriate app. So, text messages, emails, todos, meeting notes, and random ideas all start in Drafts. Unfortunately my corporate iPhone blocks iCloud Drive, so I can’t use Drafts to share notes across my devices. Anything that I want to keep gets moved into Apple Notes.
Things is on the left and is currently my favoured todo app. All of my tasks, projects, and areas of focus are in there, tagged by context, and given due dates, if appropriate. If the Things app has a notification badge, then I’ve got work to do today. If you’re keen, The Sweet Setup has a great course on Things.
A few more notes on my setup:
If Drafts isn’t the right place to start, I just pull down from the home screen to activate search and find the right app. I’ve found that the Siri Suggestions are often what I’m looking for (based on time of day and other context).
Some apps are more important for their output than input. These include calendar, weather, and notes. I’ve set these up as widgets in the Today View. A quick slide to the right reveals these.
I interact with several other apps through notifications, particularly for communication with Messages and Mail. But, I’ve set up VIPs in Mail to reduce these notifications to just the really important people.
I’ve been using this setup for a few months now and it certainly works for me. Even if this isn’t quite right for you, I’d encourage you to take a few minutes to really think through how you interact with your phone. I see far too many people with the default settings spending too much time scrolling around on their phones looking for the right app.
Like many of us, my online presence had become scattered across many sites: Twitter, Instagram, LinkedIn, Tumblr, and a close-to-defunct personal blog. So much of my content has been locked into proprietary services, each of which seemed like a good idea to start with.
Looking back at it now, I’m not happy with this and wanted to gather everything back into something that I could control. Micro.blog seems like a great home for this, as well described in this post from Manton Reece (micro.blog’s creator). So, I’ve consolidated almost everything here. All that’s left out is Facebook, which I may just leave alone.
By starting with micro.blog, I can selectively send content to other sites, while everything is still available from one source. I think this is a much better approach and I’m happy to be part of the open indie web again.
I’m very keen on backups. So many important things are digital now and, as a result, ephemeral. Fortunately you can duplicate digital assets, which makes backups helpful for preservation.
Most of my backup strategy was aimed at recovering from catastrophic loss, like a broken hard drive or stolen computer. I wasn’t sufficiently prepared for more subtle, corrosive loss of files. As a result, many videos of my kids' early years were lost. This was really hard to take, especially given that I thought I was so prepared with backups.
Fortunately, I found an old Mac Mini in a closet that had most of the missing files! This certainly wasn’t part of my backup strategy, but I’ll take it.
So, just a friendly reminder to make sure your backups are actually working as you expect. We all know this. But, please check.
My favourite spin studio has put on a fitness challenge for 2019. It has many components, one of which is improving your performance by 3% over six weeks. I’ve taken on the challenge and am now worried that I don’t know how reasonable this increase actually is. So, a perfect excuse to extract my metrics and perform some excessive analysis.
We start by importing a CSV file of my stats, taken from Torq’s website. We use readr for this and set the col_types in advance to specify the type for each column, as well as skip some extra columns with col_skip. I find doing this at the same time as the import, rather than later in the process, more direct and efficient. I also like the flexibility of the col_date import, where I can convert the source data (e.g., “Mon 11/02/19 - 6:10 AM”) into a format more useful for analysis (e.g., “2019-02-11”).
One last bit of clean up is to specify the instructors that have led 5 or more sessions. Later, we’ll try to identify an instructor-effect on my performance and only 5 of the 10 instructors have sufficient data for such an analysis. The forcats::fct_other function is really handy for this: it collapses several factor levels together into one “Other” level.
Lastly, I set the challenge_start_date variable for use later on.
## # A time tibble: 6 x 5
## # Index: Date
## Date Instructor avg_power max_power total_energy
##
## 1 2019-02-11 Justine 234 449 616
## 2 2019-02-08 George 221 707 577
## 3 2019-02-04 Justine 230 720 613
## 4 2019-02-01 George 220 609 566
## 5 2019-01-21 Justine 252 494 623
## 6 2019-01-18 George 227 808 590
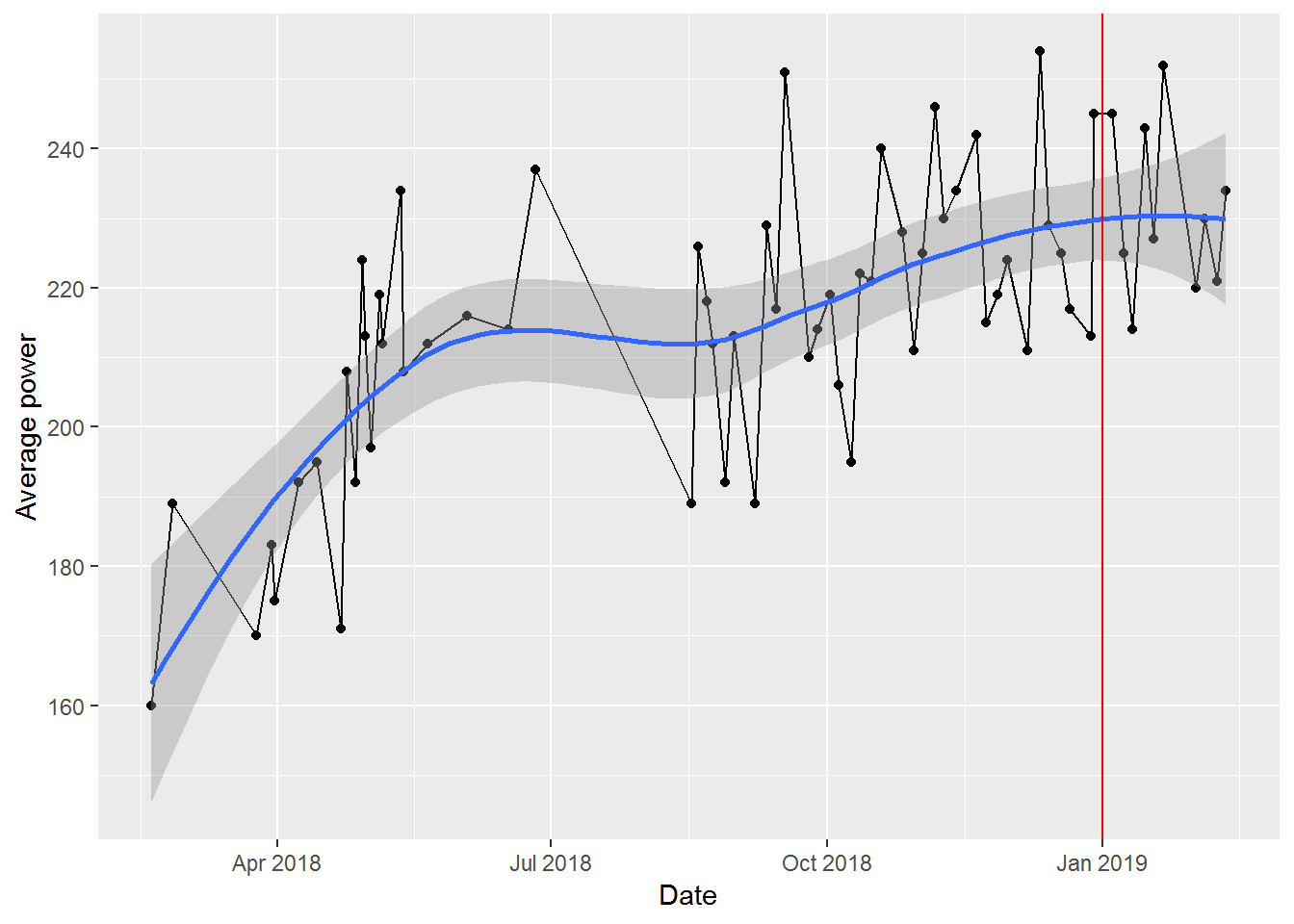
To start, we just plot the change in average power over time. Given relatively high variability from class to class, we add a smoothed line to show the overall trend. We also mark the point where the challenge starts with a red line.
Overall, looks like I made some steady progress when I started, plateaued in the Summer (when I didn’t ride as often), and then started a slow, steady increase in the Fall. Unfortunately for me, it also looks like I started to plateau in my improvement just in time for the challenge.
We’ll start a more formal analysis by just testing to see what my average improvement is over time.
time_model <- lm(avg_power ~ Date, data = data)
summary(time_model)
##
## Call:
## lm(formula = avg_power ~ Date, data = data)
##
## Residuals:
## Min 1Q Median 3Q Max
## -30.486 -11.356 -1.879 11.501 33.838
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -2.032e+03 3.285e+02 -6.186 4.85e-08 ***
## Date 1.264e-01 1.847e-02 6.844 3.49e-09 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 15.65 on 64 degrees of freedom
## Multiple R-squared: 0.4226, Adjusted R-squared: 0.4136
## F-statistic: 46.85 on 1 and 64 DF, p-value: 3.485e-09
Based on this, we can see that my performance is improving over time and the R2 is decent. But, interpreting the coefficient for time isn’t entirely intuitive and isn’t really the point of the challenge. The question is: how much higher is my average power during the challenge than before? For that, we’ll set up a “dummy variable” based on the date of the class. Then we use dplyr to group by this variable and estimate the mean of the average power in both time periods.
data %<>%
dplyr::mutate(in_challenge = ifelse(Date > challenge_start_date, 1, 0))
(change_in_power <- data %>%
dplyr::group_by(in_challenge) %>%
dplyr::summarize(mean_avg_power = mean(avg_power)))
## # A tibble: 2 x 2
## in_challenge mean_avg_power
##
## 1 0 213.
## 2 1 231.
So, I’ve improved from an average power of 213 to 231 for a improvement of 8%. A great relief: I’ve exceeded the target!
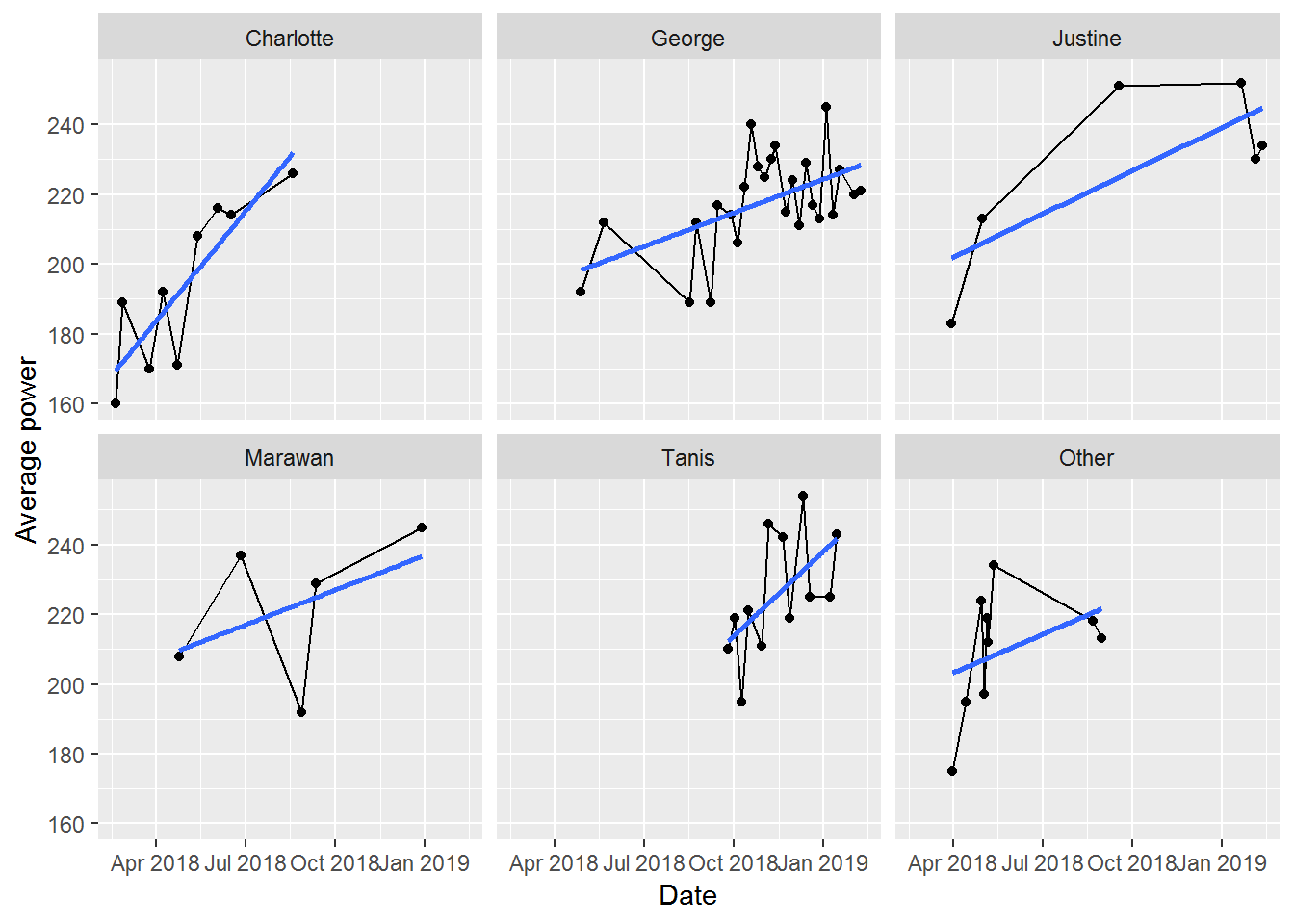
Of course, having gone to all of this (excessive?) trouble, now I’m interested in seeing if the instructor leading the class has a significant impact on my results. I certainly feel as if some instructors are harder than others. But, is this supported by my actual results? As always, we start with a plot to get a visual sense of the data.
There’s a mix of confirmation and rejection of my expectations here:
Charlotte got me started and there’s a clear trend of increasing power as I figure out the bikes and gain fitness
George’s class is always fun, but my progress isn’t as high as I’d like (indicated by the shallower slope). This is likely my fault though: George’s rides are almost always Friday morning and I’m often tired by then and don’t push myself as hard as I could
Justine hasn’t led many of my classes, but my two best results are with her. That said, my last two rides with her haven’t been great
Marawan’s classes always feel really tough. He’s great at motivation and I always feel like I’ve pushed really hard in his classes. You can sort of see this with the relatively higher position of the best fit line for his classes. But, I also had one really poor class with him. This seems to coincide with some poor classes with both Tanis and George though. So, I was likely a bit sick then. Also, for Marawan, I’m certain I’ve had more classes with him (each one is memorably challenging), as he’s substituted for other instructors several times. Looks like Torq’s tracker doesn’t adjust the name of the instructor to match this substitution though
Tanis’ classes are usually tough too. She’s relentless about increasing resistance and looks like I was improving well with her
Other isn’t really worth describing in any detail, as it is a mix of 5 other instructors each with different styles.
Having eye-balled the charts. Let’s now look at a statistical model that considers just instructors.
Each of the named instructors has a significant, positive effect on my average power. However, the overall R2 is much less than the model that considered just time. So, our next step is to consider both together.
##
## Call:
## lm(formula = avg_power ~ Date + Instructor, data = data)
##
## Residuals:
## Min 1Q Median 3Q Max
## -31.689 -11.132 1.039 10.800 26.267
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -2332.4255 464.3103 -5.023 5.00e-06 ***
## Date 0.1431 0.0263 5.442 1.07e-06 ***
## InstructorGeorge -2.3415 7.5945 -0.308 0.759
## InstructorJustine 10.7751 8.9667 1.202 0.234
## InstructorMarawan 12.5927 8.9057 1.414 0.163
## InstructorTanis 3.3827 8.4714 0.399 0.691
## InstructorOther 12.3270 7.1521 1.724 0.090 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 15.12 on 59 degrees of freedom
## Multiple R-squared: 0.5034, Adjusted R-squared: 0.4529
## F-statistic: 9.969 on 6 and 59 DF, p-value: 1.396e-07
anova(time_instructor_model, time_model)
## Analysis of Variance Table
##
## Model 1: avg_power ~ Date + Instructor
## Model 2: avg_power ~ Date
## Res.Df RSS Df Sum of Sq F Pr(>F)
## 1 59 13481
## 2 64 15675 -5 -2193.8 1.9202 0.1045
This model has the best explanatory power so far and increases the coefficient for time slightly. This suggests that controlling for instructor improves the time signal. However, when we add in time, none of the individual instructors are significantly different from each other. My interpretation of this is that my overall improvement over time is much more important than which particular instructor is leading the class. Nonetheless, the earlier analysis of the instructors gave me some insights that I can use to maximize the contribution each of them makes to my overall progress. When comparing these models with an ANOVA though, we find that there isn’t a significant difference between them.
The last model to try is to look for a time by instructor interaction.
## Analysis of Variance Table
##
## Model 1: avg_power ~ Date
## Model 2: avg_power ~ Date + Instructor + Date:Instructor
## Res.Df RSS Df Sum of Sq F Pr(>F)
## 1 64 15675
## 2 54 11920 10 3754.1 1.7006 0.1044
We can see that there are some significant interactions, meaning that the slope of improvement over time does differ by instructor. Before getting too excited though, an ANOVA shows that this model isn’t any better than the simple model of just time. There’s always a risk with trying to explain main effects (like time) with interactions. The story here is really that we need more data to tease out the impacts of the instructor by time effect.
The last point to make is that we’ve focused so far on the average power, since that’s the metric for this fitness challenge. There could be interesting interactions among average power, maximum power, RPMs, and total energy, each of which is available in these data. I’ll return to that analysis some other time.
In the interests of science, I’ll keep going to these classes, just so we can figure out what impact instructors have on performance. In the meantime, looks like I’ll succeed with at least this component of the fitness challenge and I have the stats to prove it.
This is a “behind the scenes” elaboration of the geospatial analysis in our recent post on evaluating our predictions for the 2018 mayoral election in Toronto. This was my first, serious use of the new sf package for geospatial analysis. I found the package much easier to use than some of my previous workflows for this sort of analysis, especially given its integration with the tidyverse.
We start by downloading the shapefile for voting locations from the City of Toronto’s Open Data portal and reading it with the read_sf function. Then, we pipe it to st_transform to set the appropriate projection for the data. In this case, this isn’t strictly necessary, since the shapefile is already in the right projection. But, I tend to do this for all shapefiles to avoid any oddities later.
## Simple feature collection with 1700 features and 13 fields## geometry type: POINT## dimension: XY## bbox: xmin: -79.61937 ymin: 43.59062 xmax: -79.12531 ymax: 43.83052## epsg (SRID): 4326## proj4string: +proj=longlat +datum=WGS84 +no_defs## # A tibble: 1,700 x 14## POINT_ID FEAT_CD FEAT_C_DSC PT_SHRT_CD PT_LNG_CD POINT_NAME VOTER_CNT## <dbl> <chr> <chr> <chr> <chr> <chr> <int>## 1 10190 P Primary 056 10056 <na> 37## 2 10064 P Primary 060 10060 <na> 532## 3 10999 S Secondary 058 10058 Malibu 661## 4 11342 P Primary 052 10052 <na> 1914## 5 10640 P Primary 047 10047 The Summit 956## 6 10487 S Secondary 061 04061 White Eag… 51## 7 11004 P Primary 063 04063 Holy Fami… 1510## 8 11357 P Primary 024 11024 Rosedale … 1697## 9 12044 P Primary 018 05018 Weston Pu… 1695## 10 11402 S Secondary 066 04066 Elm Grove… 93## # ... with 1,690 more rows, and 7 more variables: OBJECTID <dbl>,## # ADD_FULL <chr>, X <dbl>, Y <dbl>, LONGITUDE <dbl>, LATITUDE <dbl>,## # geometry <point>
The file has 1700 rows of data across 14 columns. The first 13 columns are data within the original shapefile. The last column is a list column that is added by sf and contains the geometry of the location. This specific design feature is what makes an sf object work really well with the rest of the tidyverse: the geographical details are just a column in the data frame. This makes the data much easier to work with than in other approaches, where the data is contained within an [@data](https://micro.blog/data) slot of an object.
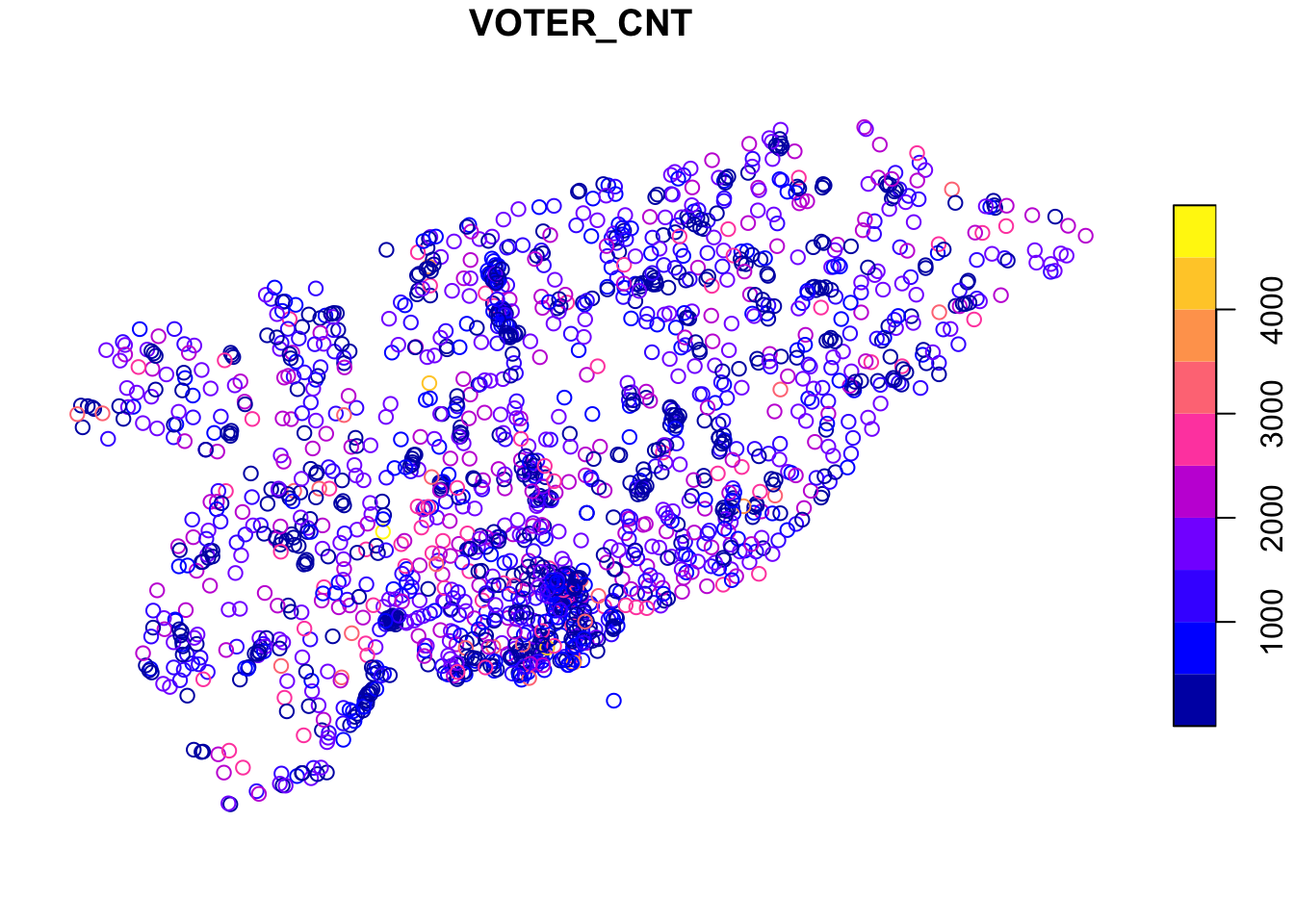
Plotting the data is straightforward, since sf objects have a plot function. Here’s an example where we plot the number of voters (VOTER_CNT) at each location. If you squint just right, you can see the general outline of Toronto in these points.
What we want to do next is use the voting location data to aggregate the votes cast at each location into census tracts. This then allows us to associate census characteristics (like age and income) with the pattern of votes and develop our statistical relationships for predicting voter behaviour.
We’ll split this into several steps. The first is downloading and reading the census tract shapefile.
Now that we have it, all we really want are the census tracts in Toronto (the shapefile includes census tracts across Canada). We achieve this by intersecting the Toronto voting locations with the census tracts using standard R subsetting notation.
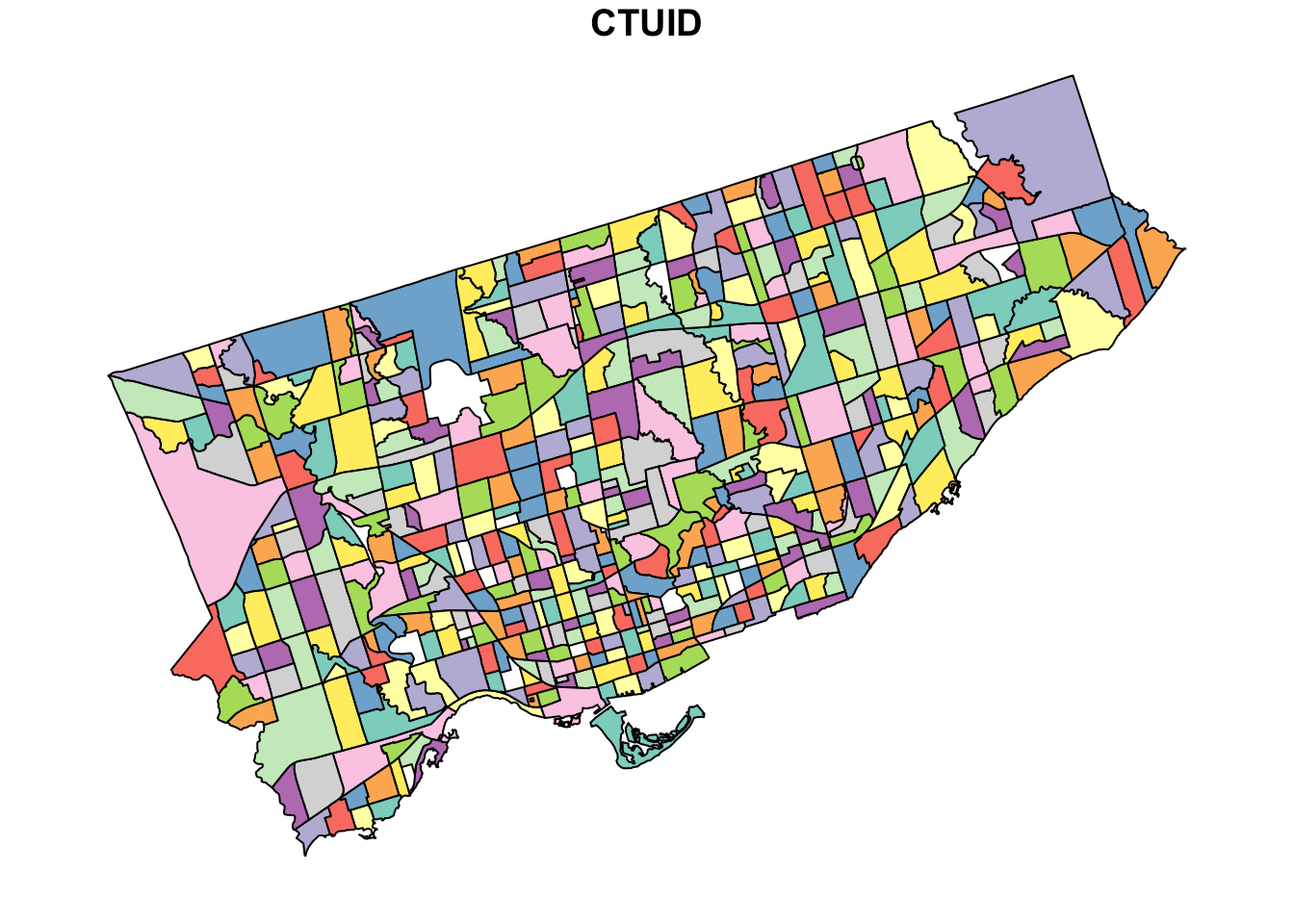
And, we can plot it to see how well the intersection worked. This time we’ll plot the CTUID, which is the unique identifier for each census tract. This doesn’t mean anything in this context, but adds some nice colour to the plot.
plot(to_census_tracts["CTUID"])
Now you can really see the shape of Toronto, as well as the size of each census tract.
Next we need to manipulate the voting data to get votes received by major candidates in the 2018 election. We take these data from the toVotes package and arbitrarily set the threshold for major candidates to receiving at least 100,000 votes. This yields our two main candidates: John Tory and Jennifer Keesmaat.
## # A tibble: 2 x 1## candidate ## <chr> ## 1 Keesmaat Jennifer## 2 Tory John
Given our goal of aggregating the votes received by each candidate into census tracts, we need a data frame that has each candidate in a separate column. We start by joining the major candidates table to the votes table. In this case, we also filter the votes to 2018, since John Tory has been a candidate in more than one election. Then we use the tidyr package to convert the table from long (with one candidate column) to wide (with a column for each candidate).
Our last step before finally aggregating to census tracts is to join the spread_votes table with the toronto_locations data. This requires pulling the ward and area identifiers from the PT_LNG_CD column of the toronto_locations data frame which we do with some stringr functions. While we’re at it, we also update the candidate names to just surnames.
Okay, we’re finally there. We have our census tract data in to_census_tracts and our voting data in to_geo_votes. We want to aggregate the votes into each census tract by summing the votes at each voting location within each census tract. We use the aggregate function for this.
ct_votes_wide <-aggregate(x = to_geo_votes,
by = to_census_tracts,
FUN = sum)
ct_votes_wide
As a last step, to tidy up, we now convert the wide table with a column for each candidate into a long table that has just one candidate column containing the name of the candidate.
Now that we have votes aggregated by census tract, we can add in many other attributes from the census data. We won’t do that here, since this post is already pretty long. But, we’ll end with a plot to show how easily sf integrates with ggplot2. This is a nice improvement from past workflows, when several steps were required. In the actual code for the retrospective analysis, I added some other plotting techniques, like cutting the response variable (votes) into equally spaced pieces and adding some more refined labels. Here, we’ll just produce a simple plot.
Our predictions for the 2018 mayoral race in Toronto were generated by our new agent-based model that used demographic characteristics and results of previous elections.
Now that the final results are available, we can see how our predictions performed at the census tract level.
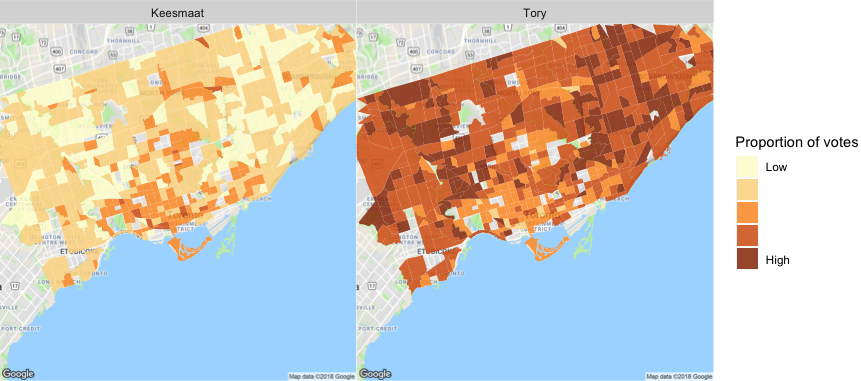
For this analysis, we restrict the comparison to just Tory and Keesmaat, as they were the only two major candidates and the only two for which we estimated vote share. Given this, we start by just plotting the difference between the actual votes and the predicted votes for Keesmaat. The distribution for Tory is simply the mirror image, since their combined share of votes always equals 100%.
Distribution of the difference between the predicted and actual proportion of votes for Keesmaat
The mean difference from the actual results for Keesmaat is -6%, which means that, on average, we slightly overestimated support for Keesmaat. However, as the histogram shows, there is significant variation in this difference across census tracts with the differences slightly skewed towards overestimating Keesmaat’s support.
To better understand this variation, we can look at a plot of the geographical distribution of the differences. In this figure, we show both Keesmaat and Tory. Although the plots are just inverted versions of each other (since the proportion of votes always sums to 100%), seeing them side by side helps illuminate the geographical structure of the differences.
The distribution of the difference between the predicted and actual proportion of votes by census tract
The overall distribution of differences doesn’t have a clear geographical bias. In some sense, this is good, as it shows our agent-based model isn’t systematically biased to any particular census tract. Rather, refinements to the model will improve accuracy across all census tracts.
We’ll write details about our new agent-based approach soon. In the meantime, these results show that the approach has promise, given that it used only a few demographic characteristics and no polls. Now we’re particularly motivated to gather up much more data to enrich our agents’ behaviour and make better predictions.
Thanks to generous support, the 4th Axe Pancreatic Cancer fundraiser was a great success. We raised over $32K this year and all funds support the PancOne Network. So far, we’ve raised close to $120K in honour of my Mom. Thanks to everyone that has supported this important cause!
It’s been a while since we last posted – largely for personal reasons, but also because we wanted to take some time to completely retool our approach to modeling elections.
In the past, we’ve tried a number of statistical approaches. Because every election is quite different to its predecessors, this proved unsatisfactory – there are simply too many things that change which can’t be effectively measured in a top-down view. Top-down approaches ultimately treat people as averages. But candidates and voters do not behave like averages; they have different desires and expectations.
We know there are diverse behaviours that need to be modeled at the person-level. We also recognize that an election is a system of diverse agents, whose behaviours affect each other. For example, a candidate can gain or lose support by doing nothing, depending only on what other candidates do. Similarly, a candidate or voter will behave differently simply based on which candidates are in the race, even without changing any beliefs. In the academic world, the aggregated results of such behaviours are called “emergent properties”, and the ability to predict such outcomes is extremely difficult if looking at the system from the top down.
So we needed to move to a bottom-up approach that would allow us to model agents heterogeneously, and that led us to what is known as agent-based modeling.
Agent-based modeling and elections
Agent-based models employ individual heterogeneous “agents” that are interconnected and follow behavioural rules defined by the modeler. Due to their non-linear approach, agent-based models have been used extensively in military games, biology, transportation planning, operational research, ecology, and, more recently, in economics (where huge investments are being made).
While we’ll write more on this in the coming weeks, we define voters’ and candidates’ behaviour using parameters, and “train” them (i.e., setting those parameters) based on how they behaved in previous elections. For our first proof of concept model, we have candidate and voter agents with two-variable issues sets (call the issues “economic” and “social”) – each with a positional score of 0 to 100. Voters have political engagement scores (used to determine whether they cast a ballot), demographic characteristics based on census data, likability scores assigned to each candidate (which include anything that isn’t based on issues, from name recognition to racial or sexual bias), and a weight for how important likability is to that voter. Voters also track, via polls, the likelihood that a candidate can win. This is important for their “utility function” – that is, the calculation that defines which candidate a voter will choose, if they cast a ballot at all. For example, a candidate that a voter may really like, but who has no chance of winning, may not get the voter’s ultimate vote. Instead, the voter may vote strategically.
On the other hand, candidates simply seek votes. Each candidate looks at the polls and asks 1) am I a viable candidate?; and 2) how do I change my positions to attract more voters? (For now, we don’t provide them a way to change their likability.) Candidates that have a chance of winning move a random angle from their current position, based on how “flexible” they are on their positions. If that move works (i.e., moves them up in the polls), they move randomly in the same general direction. If the move hurt their standings in the polls, they turn around and go randomly in the opposite general direction. At some point, the election is held – that is, the ultimate poll – and we see who wins.
This approach allows us to run elections with different candidates, change a candidate’s likability, introduce shocks (e.g., candidates changing positions on an issue) and, eventually, see how different voting systems might impact who gets elected (foreshadowing future work.)
We’re not the first to apply agent-based modeling in psephology by any stretch (there are many in the academic world using it to explain observed behaviours), but we haven’t found any attempting to do so to predict actual elections.
Applying this to the Toronto 2018 Mayoral Race
First, Toronto voters have, over the last few elections, voted somewhat more right-wing than might have been predicted. Looking at the average positions across the city for the 2003, 2006, 2010, and 2014 elections looks like the following:
This doesn’t mean that Toronto voters are themselves more right-wing than might be expected, just that they voted this way. This is in fact the first interesting outcome of our new approach. We find that about 30% of Toronto voters have been based on candidate likability, and that for the more right-wing candidates, likability has been a major reason for choosing them. For example, in 2010, Rob Ford’s likability score was significantly higher that his major competitors (George Smitherman and Joe Pantalone). This isn’t to say that everyone liked Rob Ford – but those that did vote for him cared more about something other than issues, at least relative to those who voted for his opponents.
For 2018, likability is less a differentiating factor, with both major candidates (John Tory and Jennifer Keesmaat scoring about the same on this factor). Nor are the issues – Ms. Keesmaat’s positions don’t seem to be hurting her standing in the polls as she’s staked out a strong position left of centre on both issues. What appears to be the bigger factor this time around is the early probabilities assigned by voters to Ms. Keesmaat’s chance of victory, a point that seems to have been a part of the actual Tory campaign’s strategy. Having not been seen as a major threat to John Tory by much of the city, that narrative become self-reinforcing. Further, John Tory’s positions are relatively more centrist in 2018 than they were in 2014, when he had a markedly viable right-wing opponent in Doug Ford. (To prove the point of this approach’s value, we could simply introduce a right-wing candidate and see what happens…)
Thus, our predictions don’t appear to be wildly different from current polls (with Tory winning nearly 2-to-1), and map as follows:
There will be much more to say on this, and much more we can do going forward, but for a proof of concept, we think this approach has enormous promise.
In my Elections Ontario official results post, I had to use an ugly hack to match Electoral District names and numbers by extracting data from a drop down list on the Find My Electoral District website. Although it was mildly clever, like any hack, I shouldn’t have relied on this one for long, as proven by Elections Ontario shutting down the website.
So, a more robust solution was required, which led to using one of Election Ontario’s shapefiles. The shapefile contains the data we need, it’s just in a tricky format to deal with. But, the sf package makes this mostly straightforward.
We start by downloading and importing the Elections Ontario shape file. Then, since we’re only interested in the City of Toronto boundaries, we download the city’s shapefile too and intersect it with the provincial one to get a subset:
Now we just need to extract a couple of columns from the data frame associated with the shapefile. Then we process the values a bit so that they match the format of other data sets. This includes converting them to UTF-8, formatting as title case, and replacing dashes with spaces:
## Simple feature collection with 23 features and 2 fields
## geometry type: MULTIPOINT
## dimension: XY
## bbox: xmin: -79.61919 ymin: 43.59068 xmax: -79.12511 ymax: 43.83057
## epsg (SRID): 4326
## proj4string: +proj=longlat +datum=WGS84 +no_defs
## # A tibble: 23 x 3
## electoral_distri… electoral_distric… geometry
##
## 1 005 Beaches East York (-79.32736 43.69452, -79.32495 43…
## 2 015 Davenport (-79.4605 43.68283, -79.46003 43.…
## 3 016 Don Valley East (-79.35985 43.78844, -79.3595 43.…
## 4 017 Don Valley West (-79.40592 43.75026, -79.40524 43…
## 5 020 Eglinton Lawrence (-79.46787 43.70595, -79.46376 43…
## 6 023 Etobicoke Centre (-79.58697 43.6442, -79.58561 43.…
## 7 024 Etobicoke Lakesho… (-79.56213 43.61001, -79.5594 43.…
## 8 025 Etobicoke North (-79.61919 43.72889, -79.61739 43…
## 9 068 Parkdale High Park (-79.49944 43.66285, -79.4988 43.…
## 10 072 Pickering Scarbor… (-79.18898 43.80374, -79.17927 43…
## # ... with 13 more rows
In the end, this is a much more reliable solution, though it seems a bit extreme to use GIS techniques just to get a listing of Electoral District names and numbers.
The commit with most of these changes in toVotes is here.
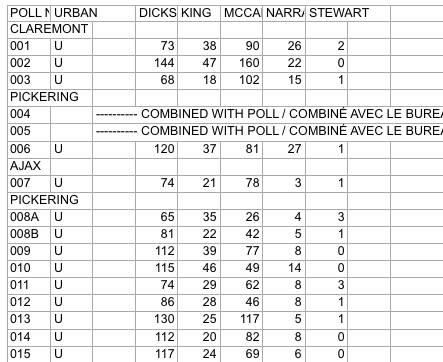
In preparing for some PsephoAnalytics work on the upcoming provincial election, I’ve been wrangling the Elections Ontario data. As provided, the data is really difficult to work with and we’ll walk through some steps to tidy these data for later analysis.
Here’s what the source data looks like:
Screenshot of raw Elections Ontario data
A few problems with this:
The data is scattered across a hundred different Excel files
Candidates are in columns with their last name as the header
Last names are not unique across all Electoral Districts, so can’t be used as a unique identifier
Electoral District names are in a row, followed by a separate row for each poll within the district
The party affiliation for each candidate isn’t included in the data
So, we have a fair bit of work to do to get to something more useful. Ideally something like:
## # A tibble: 9 x 5
## electoral_district poll candidate party votes
## <chr> <chr> <chr> <chr> <int>
## 1 X 1 A Liberal 37
## 2 X 2 B NDP 45
## 3 X 3 C PC 33
## 4 Y 1 A Liberal 71
## 5 Y 2 B NDP 37
## 6 Y 3 C PC 69
## 7 Z 1 A Liberal 28
## 8 Z 2 B NDP 15
## 9 Z 3 C PC 34
This is much easier to work with: we have one row for the votes received by each candidate at each poll, along with the Electoral District name and their party affiliation.
Candidate parties
As a first step, we need the party affiliation for each candidate. I didn’t see this information on the Elections Ontario site. So, we’ll pull the data from Wikipedia. The data on this webpage isn’t too bad. We can just use the table xpath selector to pull out the tables and then drop the ones we aren’t interested in.
```
candidate_webpage <- "https://en.wikipedia.org/wiki/Ontario_general_election,_2014#Candidates_by_region"
candidate_tables <- "table" # Use an xpath selector to get the drop down list by ID
candidates <- xml2::read_html(candidate_webpage) %>%
rvest::html_nodes(candidate_tables) %>% # Pull tables from the wikipedia entry
.[13:25] %>% # Drop unecessary tables
rvest::html_table(fill = TRUE)
</pre>
<p>This gives us a list of 13 data frames, one for each table on the webpage. Now we cycle through each of these and stack them into one data frame. Unfortunately, the tables aren’t consistent in the number of columns. So, the approach is a bit messy and we process each one in a loop.</p>
<pre class="r"><code># Setup empty dataframe to store results
candidate_parties <- tibble::as_tibble(
electoral_district_name = NULL,
party = NULL,
candidate = NULL
)
for(i in seq_along(1:length(candidates))) { # Messy, but works
this_table <- candidates[[i]]
# The header spans mess up the header row, so renaming
names(this_table) <- c(this_table[1,-c(3,4)], "NA", "Incumbent")
# Get rid of the blank spacer columns
this_table <- this_table[-1, ]
# Drop the NA columns by keeping only odd columns
this_table <- this_table[,seq(from = 1, to = dim(this_table)[2], by = 2)]
this_table %<>%
tidyr::gather(party, candidate, -`Electoral District`) %>%
dplyr::rename(electoral_district_name = `Electoral District`) %>%
dplyr::filter(party != "Incumbent")
candidate_parties <- dplyr::bind_rows(candidate_parties, this_table)
}
candidate_parties</code></pre>
<pre>
# A tibble: 649 x 3
electoral_district_name party candidate
1 Carleton—Mississippi Mills Liberal Rosalyn Stevens
2 Nepean—Carleton Liberal Jack Uppal
3 Ottawa Centre Liberal Yasir Naqvi
4 Ottawa—Orléans Liberal Marie-France Lalonde
5 Ottawa South Liberal John Fraser
6 Ottawa—Vanier Liberal Madeleine Meilleur
7 Ottawa West—Nepean Liberal Bob Chiarelli
8 Carleton—Mississippi Mills PC Jack MacLaren
9 Nepean—Carleton PC Lisa MacLeod
10 Ottawa Centre PC Rob Dekker
# … with 639 more rows
</pre>
</div>
<div id="electoral-district-names" class="section level2">
<h2>Electoral district names</h2>
<p>One issue with pulling party affiliations from Wikipedia is that candidates are organized by Electoral District <em>names</em>. But the voting results are organized by Electoral District <em>number</em>. I couldn’t find an appropriate resource on the Elections Ontario site. Rather, here we pull the names and numbers of the Electoral Districts from the <a href="https://www3.elections.on.ca/internetapp/FYED_Error.aspx?lang=en-ca">Find My Electoral District</a> website. The xpath selector is a bit tricky for this one. The <code>ed_xpath</code> object below actually pulls content from the drop down list that appears when you choose an Electoral District. One nuisance with these data is that Elections Ontario uses <code>--</code> in the Electoral District names, instead of the — used on Wikipedia. We use <code>str_replace_all</code> to fix this below.</p>
<pre class="r"><code>ed_webpage <- "https://www3.elections.on.ca/internetapp/FYED_Error.aspx?lang=en-ca"
ed_xpath <- "//*[(@id = \"ddlElectoralDistricts\")]" # Use an xpath selector to get the drop down list by ID
electoral_districts <- xml2::read_html(ed_webpage) %>%
rvest::html_node(xpath = ed_xpath) %>%
rvest::html_nodes("option") %>%
rvest::html_text() %>%
.[-1] %>% # Drop the first item on the list ("Select...")
tibble::as.tibble() %>% # Convert to a data frame and split into ID number and name
tidyr::separate(value, c("electoral_district", "electoral_district_name"),
sep = " ",
extra = "merge") %>%
# Clean up district names for later matching and presentation
dplyr::mutate(electoral_district_name = stringr::str_to_title(
stringr::str_replace_all(electoral_district_name, "--", "—")))
electoral_districts</code></pre>
<pre>
# A tibble: 107 x 2
electoral_district electoral_district_name
1 001 Ajax—Pickering
2 002 Algoma—Manitoulin
3 003 Ancaster—Dundas—Flamborough—Westdale
4 004 Barrie
5 005 Beaches—East York
6 006 Bramalea—Gore—Malton
7 007 Brampton—Springdale
8 008 Brampton West
9 009 Brant
10 010 Bruce—Grey—Owen Sound
# … with 97 more rows
</pre>
<p>Next, we can join the party affiliations to the Electoral District names to join candidates to parties and district numbers.</p>
<pre class="r"><code>candidate_parties %<>%
# These three lines are cleaning up hyphens and dashes, seems overly complicated
dplyr::mutate(electoral_district_name = stringr::str_replace_all(electoral_district_name, "—\n", "—")) %>%
dplyr::mutate(electoral_district_name = stringr::str_replace_all(electoral_district_name,
"Chatham-Kent—Essex",
"Chatham—Kent—Essex")) %>%
dplyr::mutate(electoral_district_name = stringr::str_to_title(electoral_district_name)) %>%
dplyr::left_join(electoral_districts) %>%
dplyr::filter(!candidate == "") %>%
# Since the vote data are identified by last names, we split candidate's names into first and last
tidyr::separate(candidate, into = c("first","candidate"), extra = "merge", remove = TRUE) %>%
dplyr::select(-first)</code></pre>
<pre><code>## Joining, by = "electoral_district_name"</code></pre>
<pre class="r"><code>candidate_parties</code></pre>
<pre>
# A tibble: 578 x 4
electoral_district_name party candidate electoral_district
*
1 Carleton—Mississippi Mills Liberal Stevens 013
2 Nepean—Carleton Liberal Uppal 052
3 Ottawa Centre Liberal Naqvi 062
4 Ottawa—Orléans Liberal France Lalonde 063
5 Ottawa South Liberal Fraser 064
6 Ottawa—Vanier Liberal Meilleur 065
7 Ottawa West—Nepean Liberal Chiarelli 066
8 Carleton—Mississippi Mills PC MacLaren 013
9 Nepean—Carleton PC MacLeod 052
10 Ottawa Centre PC Dekker 062
# … with 568 more rows
</pre>
<p>All that work just to get the name of each candiate for each Electoral District name and number, plus their party affiliation.</p>
</div>
<div id="votes" class="section level2">
<h2>Votes</h2>
<p>Now we can finally get to the actual voting data. These are made available as a collection of Excel files in a compressed folder. To avoid downloading it more than once, we wrap the call in an <code>if</code> statement that first checks to see if we already have the file. We also rename the file to something more manageable.</p>
<pre class="r"><code>raw_results_file <- "[www.elections.on.ca/content/d...](http://www.elections.on.ca/content/dam/NGW/sitecontent/2017/results/Poll%20by%20Poll%20Results%20-%20Excel.zip)"
zip_file <- "data-raw/Poll%20by%20Poll%20Results%20-%20Excel.zip"
if(file.exists(zip_file)) { # Only download the data once
# File exists, so nothing to do
} else {
download.file(raw_results_file,
destfile = zip_file)
unzip(zip_file, exdir="data-raw") # Extract the data into data-raw
file.rename("data-raw/GE Results - 2014 (unconverted)", "data-raw/pollresults")
}</code></pre>
<pre><code>## NULL</code></pre>
<p>Now we need to extract the votes out of 107 Excel files. The combination of <code>purrr</code> and <code>readxl</code> packages is great for this. In case we want to filter to just a few of the files (perhaps to target a range of Electoral Districts), we declare a <code>file_pattern</code>. For now, we just set it to any xls file that ends with three digits preceeded by a “_“.</p>
<p>As we read in the Excel files, we clean up lots of blank columns and headers. Then we convert to a long table and drop total and blank rows. Also, rather than try to align the Electoral District name rows with their polls, we use the name of the Excel file to pull out the Electoral District number. Then we join with the <code>electoral_districts</code> table to pull in the Electoral District names.</p>
<pre class="r">
file_pattern <- “*_[[:digit:]]{3}.xls” # Can use this to filter down to specific files
poll_data <- list.files(path = “data-raw/pollresults”, pattern = file_pattern, full.names = TRUE) %>% # Find all files that match the pattern
purrr::set_names() %>%
purrr::map_df(readxl::read_excel, sheet = 1, col_types = “text”, .id = “file”) %>% # Import each file and merge into a dataframe
Specifying sheet = 1 just to be clear we’re ignoring the rest of the sheets
Declare col_types since there are duplicate surnames and map_df can’t recast column types in the rbind
For example, Bell is in both district 014 and 063
dplyr::select(-starts_with(“X__")) %>% # Drop all of the blank columns
dplyr::select(1:2,4:8,15:dim(.)[2]) %>% # Reorganize a bit and drop unneeded columns
dplyr::rename(poll_number = POLL NO.) %>%
tidyr::gather(candidate, votes, -file, -poll_number) %>% # Convert to a long table
dplyr::filter(!is.na(votes),
poll_number != “Totals”) %>%
dplyr::mutate(electoral_district = stringr::str_extract(file, “[[:digit:]]{3}"),
votes = as.numeric(votes)) %>%
dplyr::select(-file) %>%
dplyr::left_join(electoral_districts)
poll_data
</pre>
<p>The only thing left to do is to join <code>poll_data</code> with <code>candidate_parties</code> to add party affiliation to each candidate. Because the names don’t always exactly match between these two tables, we use the <code>fuzzyjoin</code> package to join by closest spelling.</p>
<pre class="r"><code>poll_data_party_match_table <- poll_data %>%
group_by(candidate, electoral_district_name) %>%
summarise() %>%
fuzzyjoin::stringdist_left_join(candidate_parties,
ignore_case = TRUE) %>%
dplyr::select(candidate = candidate.x,
party = party,
electoral_district = electoral_district) %>%
dplyr::filter(!is.na(party))
poll_data %<>%
dplyr::left_join(poll_data_party_match_table) %>%
dplyr::group_by(electoral_district, party)
tibble::glimpse(poll_data)</code></pre>
<pre>
</pre>
<p>And, there we go. One table with a row for the votes received by each candidate at each poll. It would have been great if Elections Ontario released data in this format and we could have avoided all of this work.</p>
</div>
Analyzing these data was a great case study for the typical data management process. The data was structured for presentation, rather than analysis. So, there were several header rows, notes at the base of the table, and the data was spread across many worksheets.
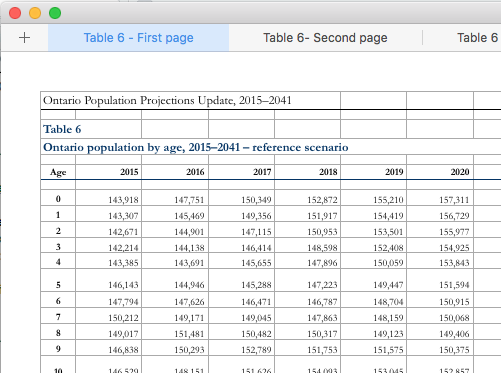
Sometime recently, the ministry released an update that provides the data in a much better format: one sheet with rows for age and columns for years. Although this is a great improvement, I’ve had to update my case study, which makes it actually less useful as a lesson in data manipulation.
Although I’ve updated the main branch of the github repository, I’ve also created a branch that sources the archive.org version of the page from October 2016. Now, depending on the audience, I can choose the case study that has the right level of complexity.
Despite briefly causing me some trouble, I think it is great that these data are closer to a good analytical format. Now, if only the ministry could go one more step towards tidy data and make my case study completely unecessary.
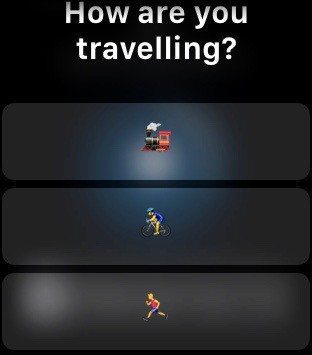
Sometimes it’s the small things, accumulated over many days, that make a difference. As a simple example, every day when I leave the office, I message my family to let them know I’m leaving and how I’m travelling. Relatively easy: just open the Messages app, find the most recent conversation with them, and type in my message.
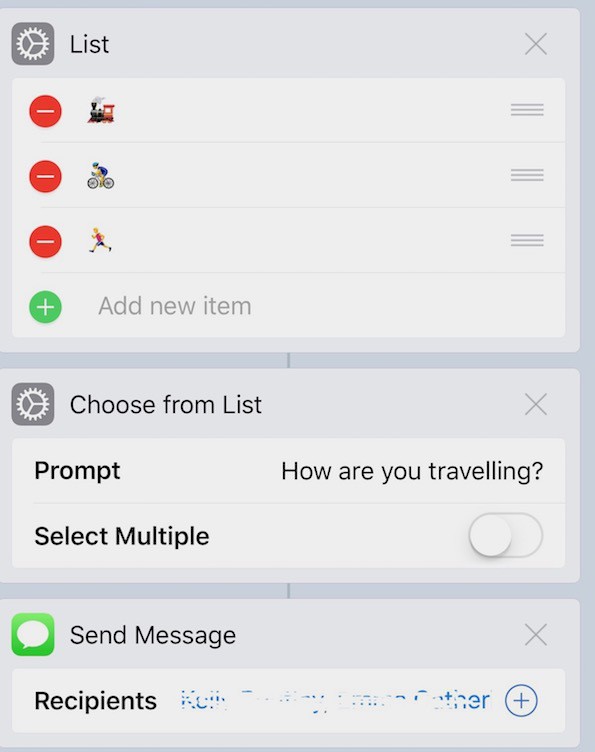
Using Workflow I can get this down to just a couple of taps on my watch. By choosing the “Leaving Work” workflow, I get a choice of travelling options:
Choosing one of them creates a text with the right emoticon that is pre-addressed to my family. I hit send and off goes the message.
The workflow itself is straightforward:
Like I said, pretty simple. But saves me close to a minute each and every day.












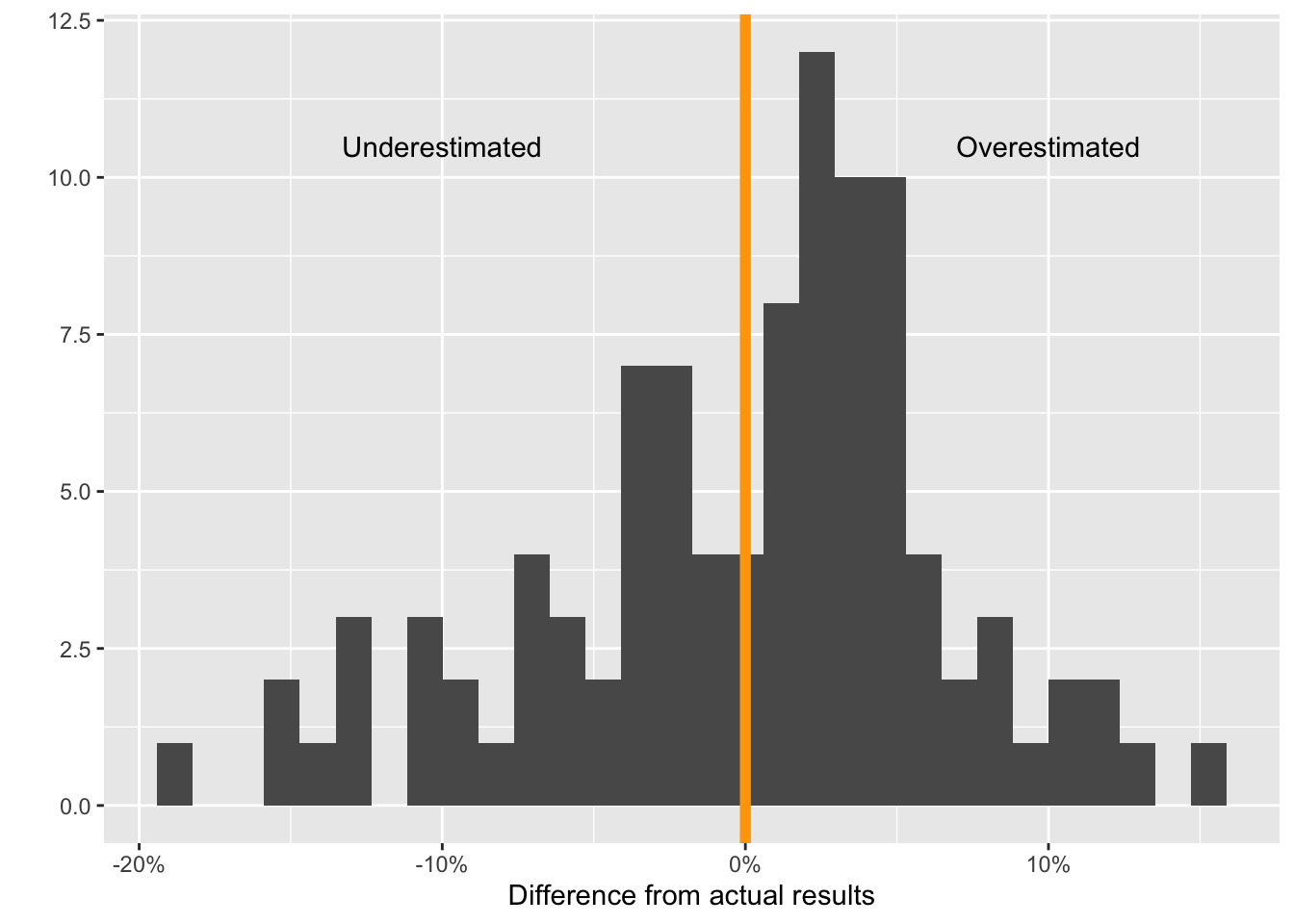 Distribution of the difference between the predicted and actual proportion of votes for all parties
Distribution of the difference between the predicted and actual proportion of votes for all parties
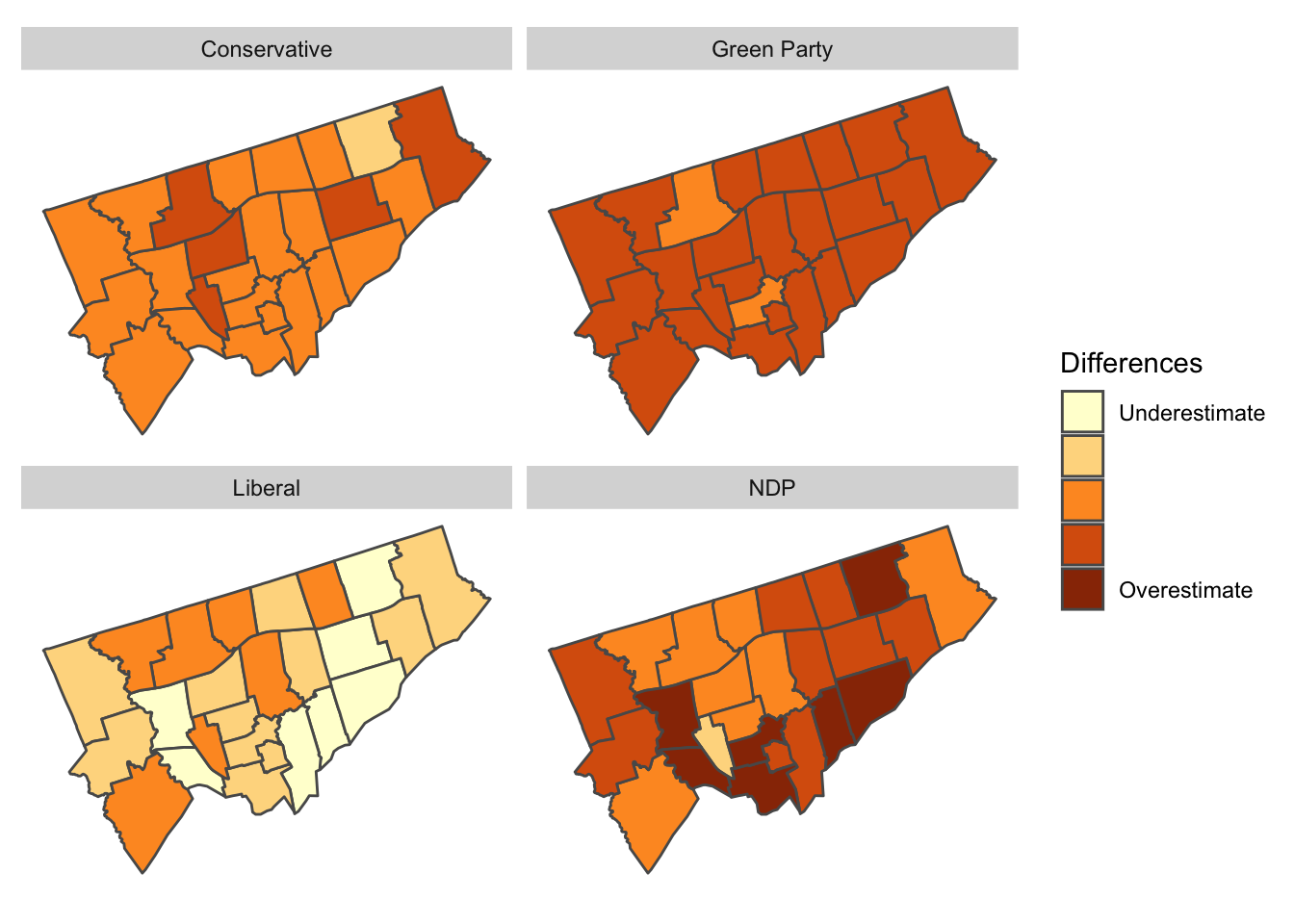 Geographical distribution of the difference between the predicted and actual proportion of votes by Electoral District and party
Geographical distribution of the difference between the predicted and actual proportion of votes by Electoral District and party

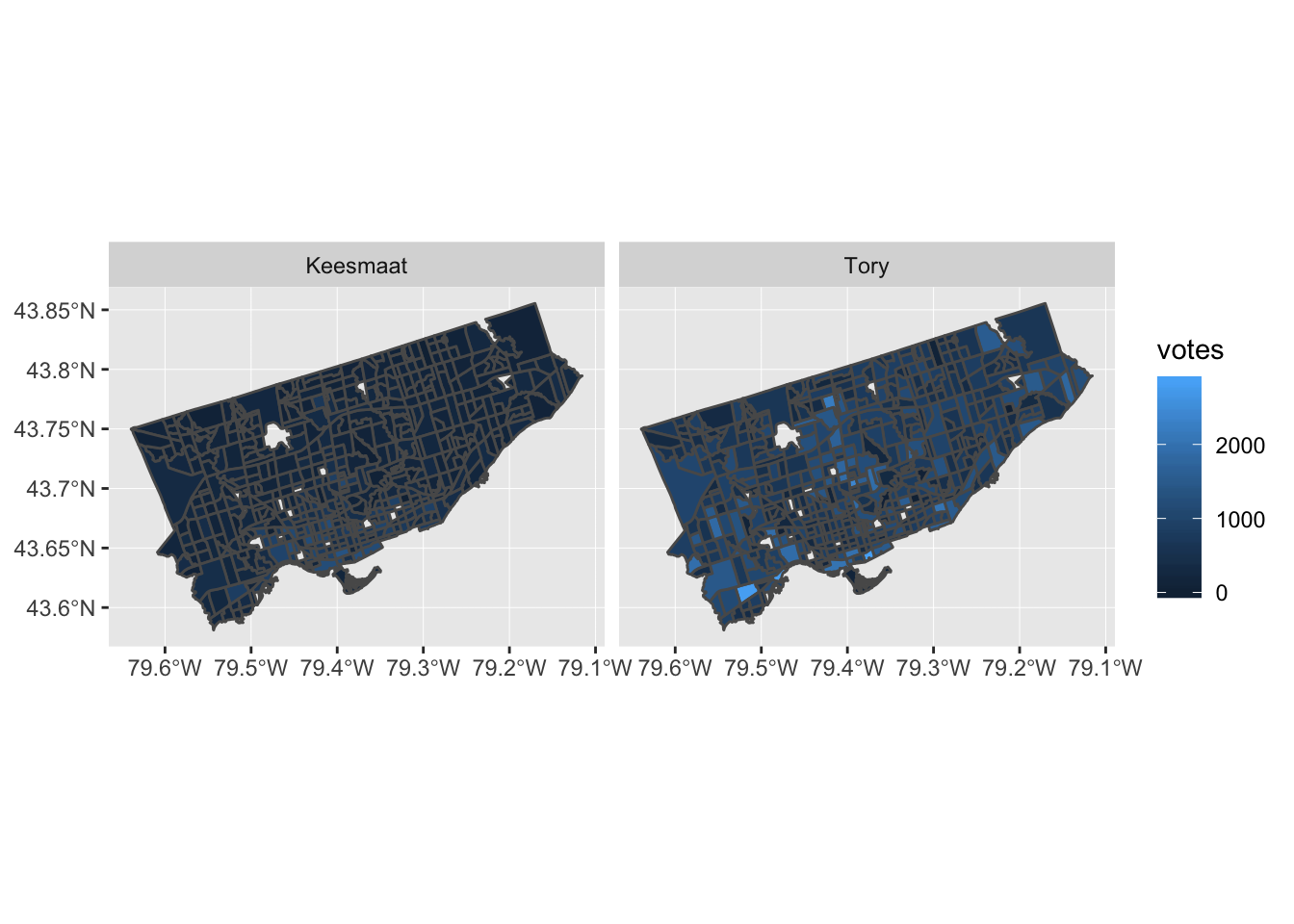
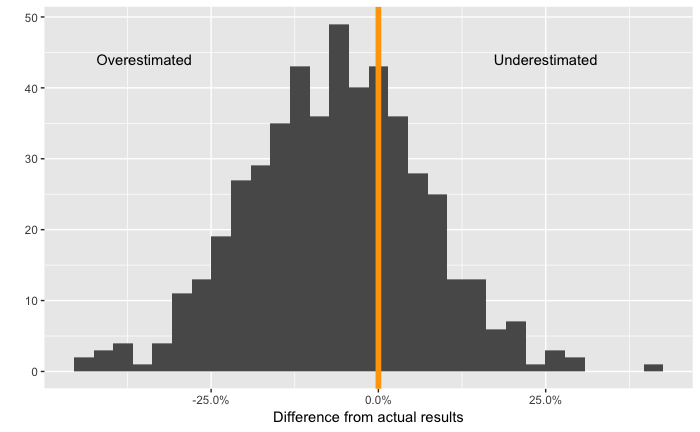 Distribution of the difference between the predicted and actual proportion of votes for Keesmaat
Distribution of the difference between the predicted and actual proportion of votes for Keesmaat
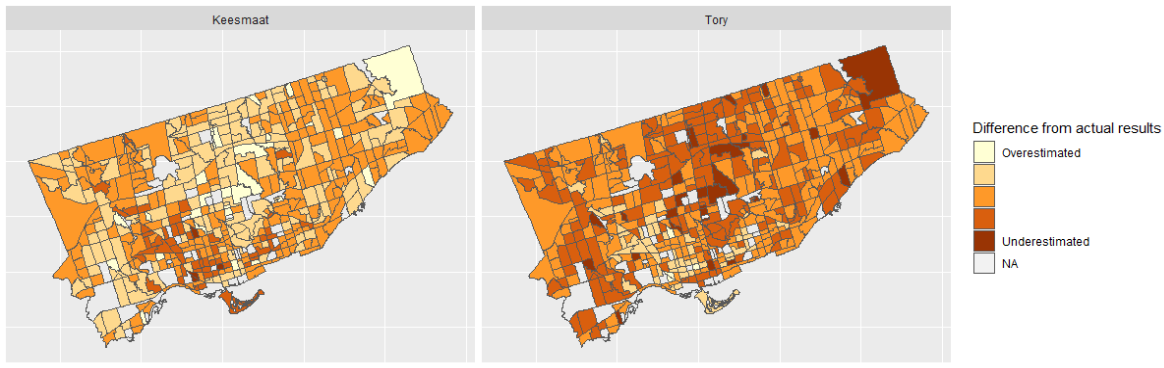 The distribution of the difference between the predicted and actual proportion of votes by census tract
The distribution of the difference between the predicted and actual proportion of votes by census tract