Many people took issue with the fact that these values weren’t adjusted for income. Seems to me that whether this is a good idea or not depends on what kind of question you’re trying to answer. Regardless, the CANSIM table includes this value. So, it is straightforward to calculate. Plus CANSIM tables have a pretty standard structure and showing how to manipulate this one serves as a good template for others.
library(tidyverse)
# Download and extract
url <- "[www20.statcan.gc.ca/tables-ta...](http://www20.statcan.gc.ca/tables-tableaux/cansim/csv/01110001-eng.zip)"
zip_file <- "01110001-eng.zip"
download.file(url,
destfile = zip_file)
unzip(zip_file)
# We only want two of the columns. Specifying them here.
keep_data <- c("Median donations (dollars)",
"Median total income of donors (dollars)")
cansim <- read_csv("01110001-eng.csv") %>%
filter(DON %in% keep_data,
is.na(`Geographical classification`)) %>% # This second filter removes anything that isn't a province or territory
select(Ref_Date, DON, Value, GEO) %>%
spread(DON, Value) %>%
rename(year = Ref_Date,
donation = `Median donations (dollars)`,
income = `Median total income of donors (dollars)`) %>%
mutate(donation_per_income = donation / income) %>%
filter(year == 2015) %>%
select(GEO, donation, donation_per_income)
cansim
## # A tibble: 16 x 3
## GEO donation donation_per_income
##
## 1 Alberta 450 0.006378455
## 2 British Columbia 430 0.007412515
## 3 Canada 300 0.005119454
## 4 Manitoba 420 0.008032129
## 5 New Brunswick 310 0.006187625
## 6 Newfoundland and Labrador 360 0.007001167
## 7 Non CMA-CA, Northwest Territories 480 0.004768528
## 8 Non CMA-CA, Yukon 310 0.004643499
## 9 Northwest Territories 400 0.003940887
## 10 Nova Scotia 340 0.006505932
## 11 Nunavut 570 0.005651398
## 12 Ontario 360 0.005856515
## 13 Prince Edward Island 400 0.008221994
## 14 Quebec 130 0.002452830
## 15 Saskatchewan 410 0.006910501
## 16 Yukon 420 0.005695688
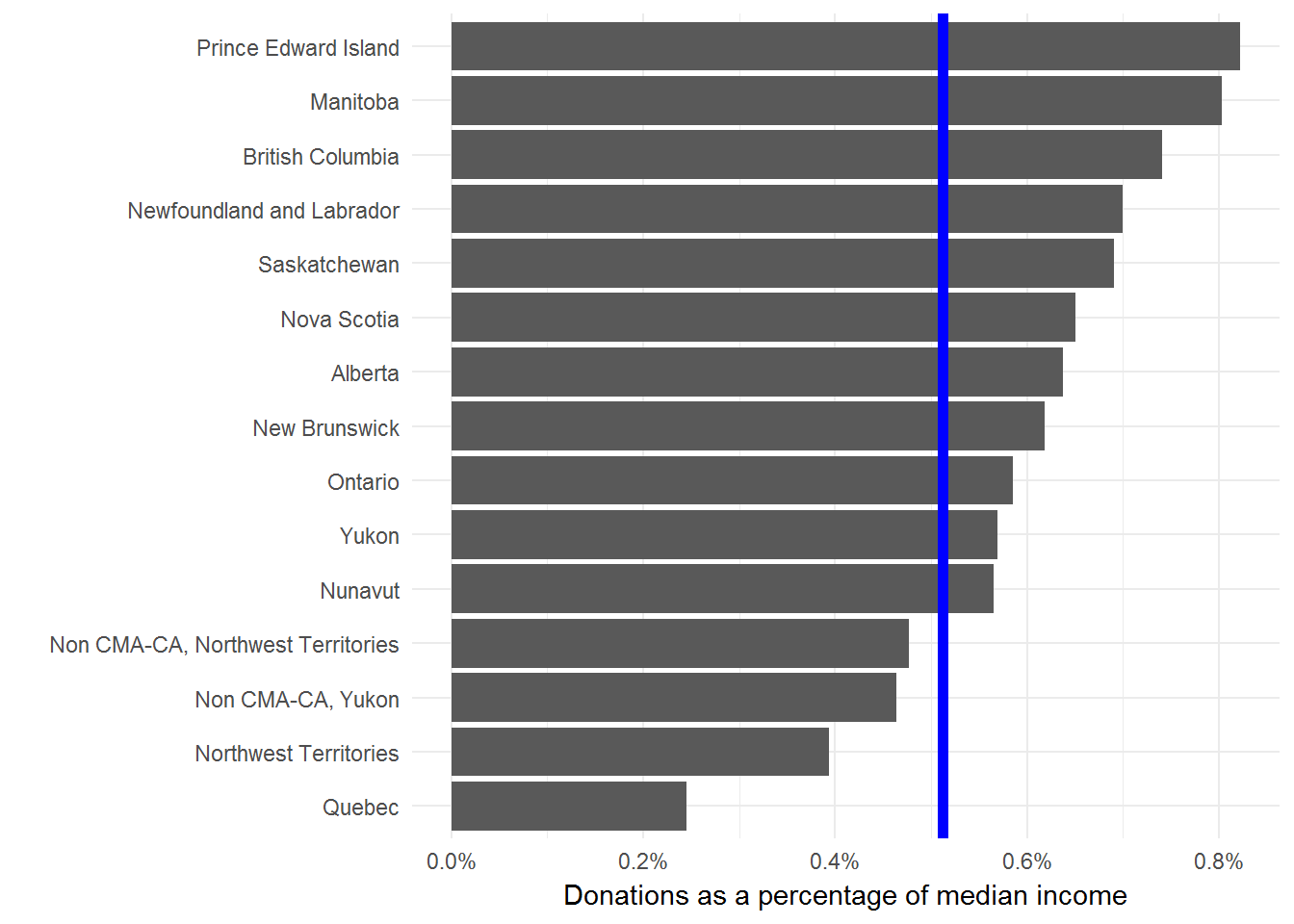
Curious that they dropped the territories from their chart, given that Nunavut has such a high donation amount.
Now we can plot the normalized data to find how the rank order changes. We’ll add the Canadian average as a blue line for comparison.
I’m not comfortable with using median donations (adjusted for income or not) to say anything in particular about the residents of a province. But, I’m always happy to look more closely at data and provide some context for public debates.
One major gap with this type of analysis is that we’re only looking at the median donations of people that donated anything at all. In other words, we aren’t considering anyone who donates nothing. We should really compare these median donations to the total population or the size of the economy. This Stats Can study is a much more thorough look at the issue.
For me the interesting result here is the dramatic difference between Quebec and the rest of the provinces. But, I don’t interpret this to mean that Quebecers are less generous than the rest of Canada. Seems more likely that there are material differences in how the Quebec economy and social safety nets are structured.
The TTC releasing their Subway Delay Data was great news. I’m always happy to see more data released to the public. In this case, it also helps us investigate one of the great, enduring mysteries: Is Friday the 13th actually an unlucky day?
As always, we start by downloading and manipulating the data. I’ve added in two steps that aren’t strictly necessary. One is converting the Date, Time, and Day columns into a single Date column. The other is to drop most of the other columns of data, since we aren’t interested in them here.
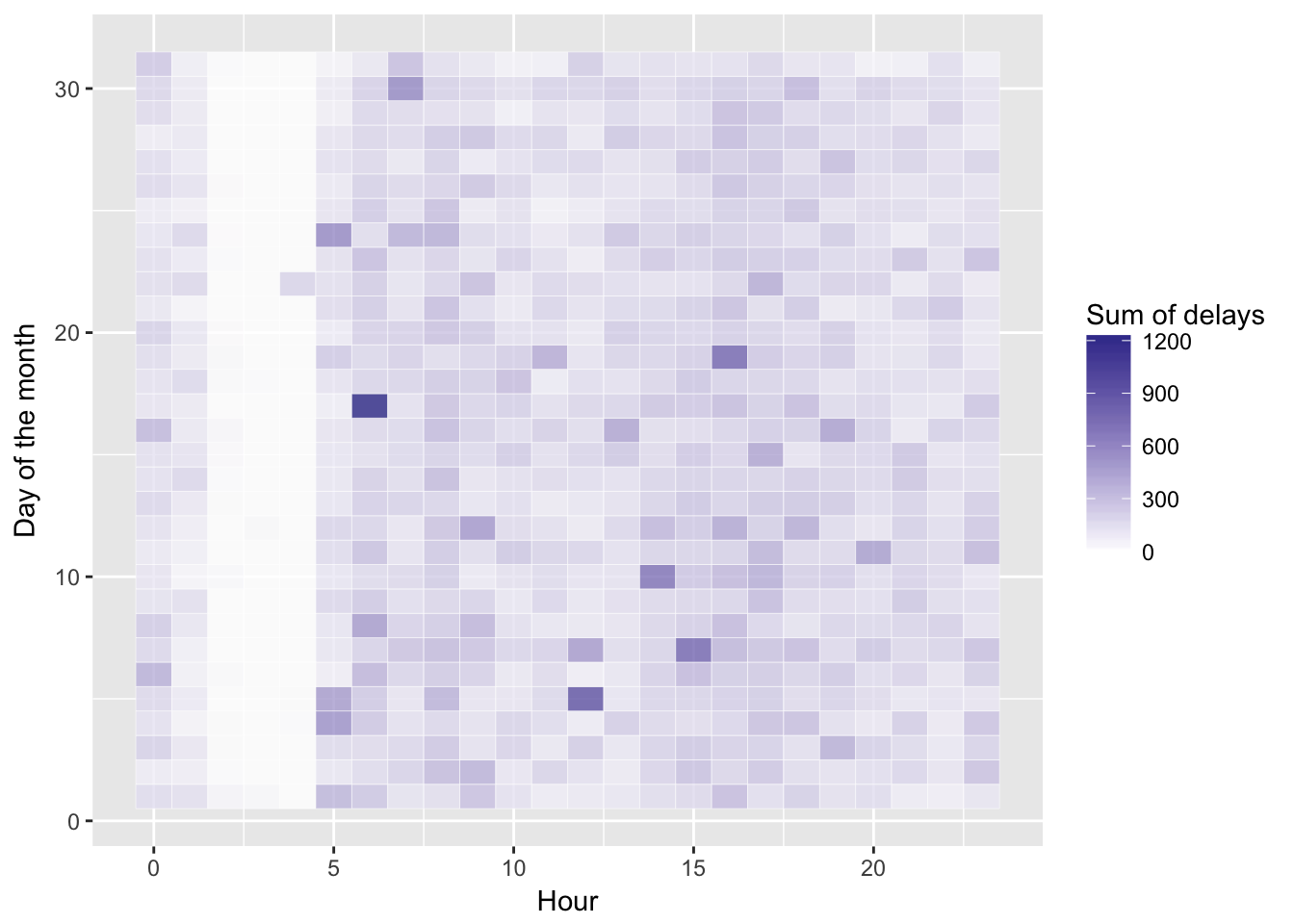
Now we have a delays dataframe with 69043 incidents starting from 2014-01-01 00:21:00 and ending at 2017-04-30 22:13:00. Before we get too far, we’ll take a look at the data. A heatmap of delays by day and hour should give us some perspective.
delays %>%
dplyr::mutate(day = lubridate::day(date),
hour = lubridate::hour(date)) %>%
dplyr::group_by(day, hour) %>%
dplyr::summarise(sum_delay =sum(delay)) %>%
ggplot2::ggplot(aes(x = hour, y = day, fill = sum_delay)) +
ggplot2::geom_tile(alpha =0.8, color ="white") +
ggplot2::scale_fill_gradient2() +
ggplot2::theme(legend.position ="right") +
ggplot2::labs(x ="Hour", y ="Day of the month", fill ="Sum of delays")
Other than a reliable band of calm very early in the morning, no obvious patterns here.
We need to identify any days that are a Friday the 13th. We also might want to compare weekends, regular Fridays, other weekdays, and Friday the 13ths, so we add a type column that provides these values. Here we use the case_when function:
delays <- delays %>%
dplyr::mutate(type =case_when( # Partition into Friday the 13ths, Fridays, weekends, and weekdays
lubridate::wday(.$date) %in%c(1, 7) ~"weekend",
lubridate::wday(.$date) %in%c(6) &
lubridate::day(.$date) ==13~"Friday 13th",
lubridate::wday(.$date) %in%c(6) ~"Friday",
TRUE~"weekday"# Everything else is a weekday
)) %>%
dplyr::mutate(type =factor(type)) %>%
dplyr::group_by(type)
delays
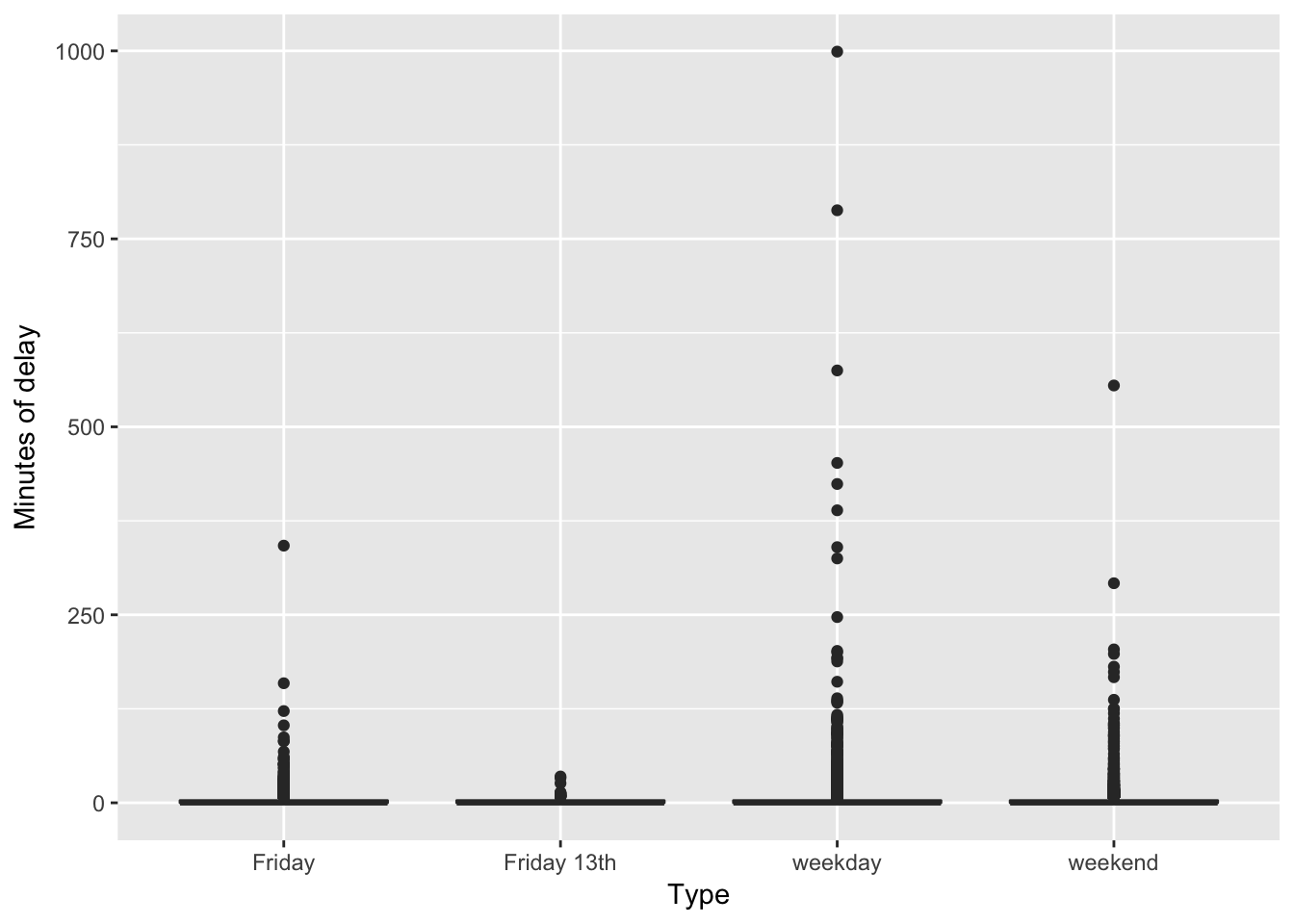
## # A tibble: 4 x 2## type total_delay## <fctr> <dbl>## 1 Friday 18036## 2 Friday 13th 619## 3 weekday 78865## 4 weekend 28194
Clearly the total minutes of delays are much shorter for Friday the 13ths. But, there aren’t very many such days (only 6 in fact). So, this is a dubious analysis.
Let’s take a step back and calculate the average of the total delay across the entire day for each of the types of days. If Friday the 13ths really are unlucky, we would expect to see longer delays, at least relative to a regular Friday.
daily_delays <- delays %>%# Total delays in a day
dplyr::mutate(year = lubridate::year(date),
day = lubridate::yday(date)) %>%
dplyr::group_by(year, day, type) %>%
dplyr::summarise(total_delay =sum(delay))
mean_daily_delays <- daily_delays %>%# Average delays in each type of day
dplyr::group_by(type) %>%
dplyr::summarise(avg_delay =mean(total_delay))
mean_daily_delays
## # A tibble: 4 x 2## type avg_delay## <fctr> <dbl>## 1 Friday 107.35714## 2 Friday 13th 103.16667## 3 weekday 113.63833## 4 weekend 81.01724
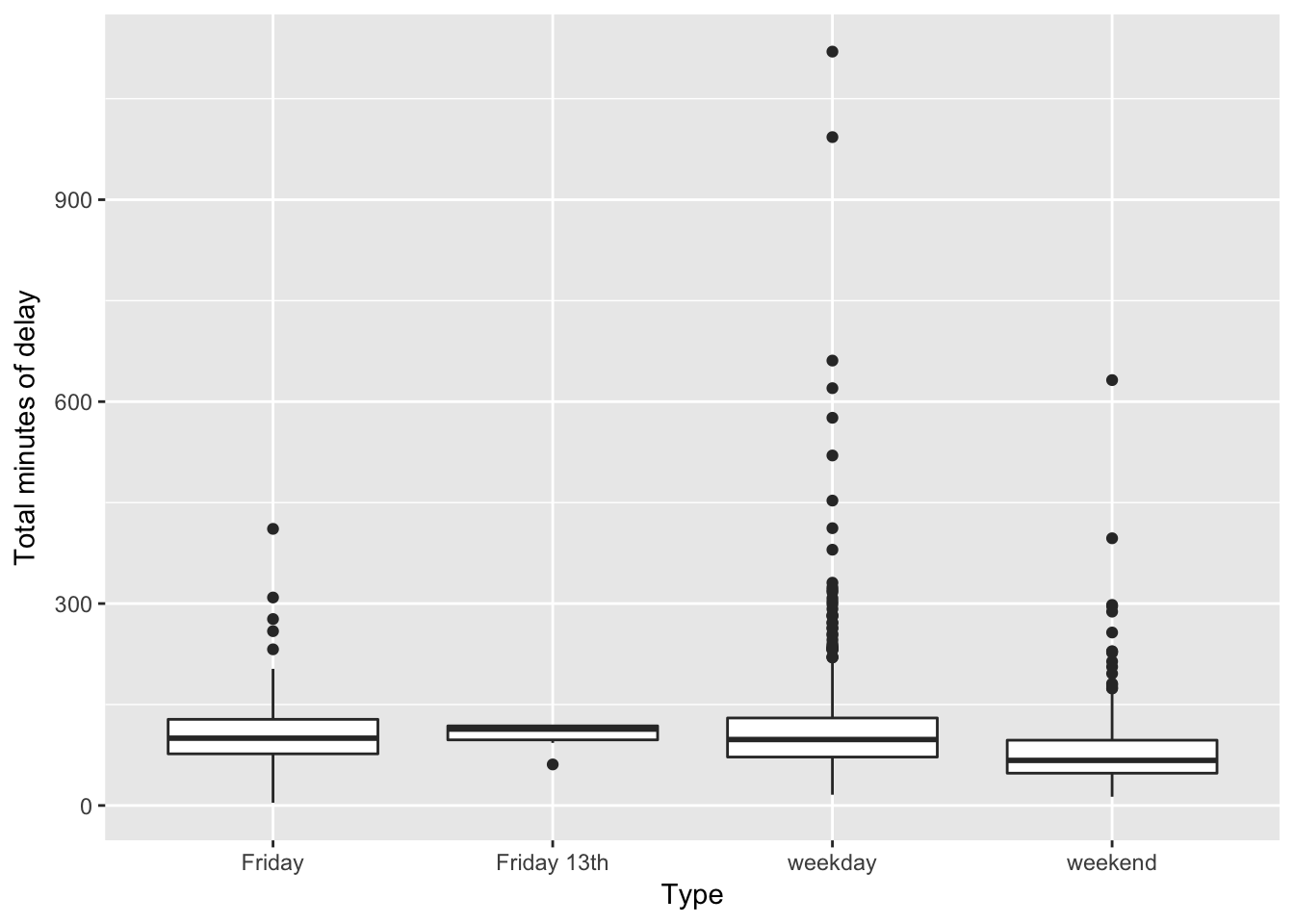
ggplot2::ggplot(daily_delays, aes(type, total_delay)) +
ggplot2::geom_boxplot() +
ggplot2::labs(x ="Type", y ="Total minutes of delay")
On average, Friday the 13ths have shorter total delays (103 minutes) than either regular Fridays (107 minutes) or other weekdays (114 minutes). Overall, weekend days have far shorter total delays (81 minutes).
If Friday the 13ths are unlucky, they certainly aren’t causing longer TTC delays.
For the statisticians among you that still aren’t convinced, we’ll run a basic linear model to compare Friday the 13ths with regular Fridays. This should control for many unmeasured variables.
model <-lm(total_delay ~ type, data = daily_delays,
subset = type %in%c("Friday", "Friday 13th"))
summary(model)
## ## Call:## lm(formula = total_delay ~ type, data = daily_delays, subset = type %in% ## c("Friday", "Friday 13th"))## ## Residuals:## Min 1Q Median 3Q Max ## -103.357 -30.357 -6.857 18.643 303.643 ## ## Coefficients:## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 107.357 3.858 27.829 <2e-16 ***## typeFriday 13th -4.190 20.775 -0.202 0.84 ## ---## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1## ## Residual standard error: 50 on 172 degrees of freedom## Multiple R-squared: 0.0002365, Adjusted R-squared: -0.005576 ## F-statistic: 0.04069 on 1 and 172 DF, p-value: 0.8404
Definitely no statistical support for the idea that Friday the 13ths cause longer TTC delays.
How about time series tests, like anomaly detections? Seems like we’d just be getting carried away. Part of the art of statistics is knowing when to quit.
In conclusion, then, after likely far too much analysis, we find no evidence that Friday the 13ths cause an increase in the length of TTC delays. This certainly suggests that Friday the 13ths are not unlucky in any meaningful way, at least for TTC riders.
Thank you to all the participants, donors, and volunteers for making the third Axe Pancreatic Cancer event such a great success! Together we’re raising awareness and funding to support Pancreatic Cancer Canada.
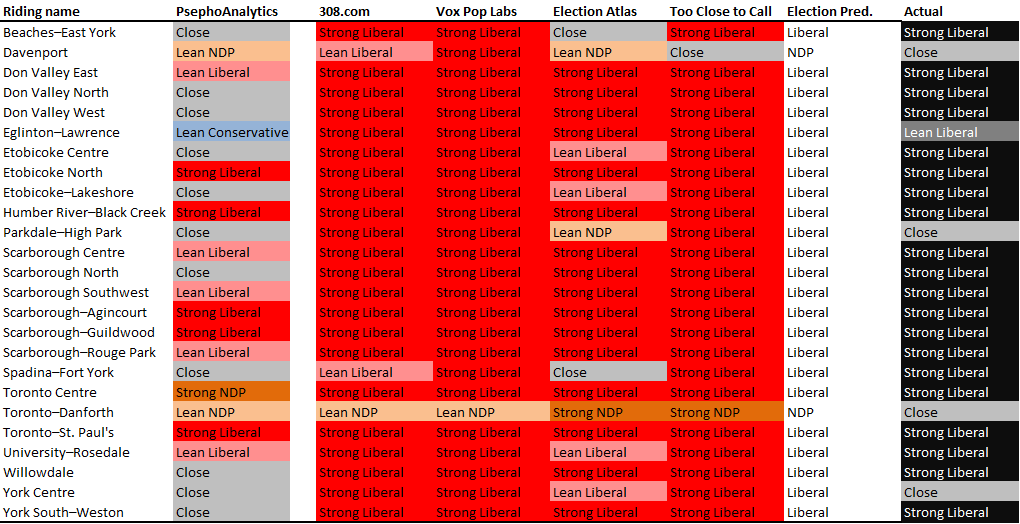
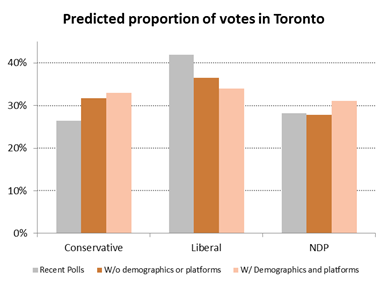
The day after an historic landslide electoral victory for the Liberal Party of Canada, we’ve compared our predictions (and those of other organizations who provide riding-level predictions) to the actual results in Toronto.
Before getting to the details, we thought it important to highlight that while the methodologies of the other organizations differ, they are all based on tracking sentiments as the campaign unfolds. So, most columns in the table below will differ slightly from the one in our previous post as such sentiments change day to day.
This is fundamentally different from our modelling approach, which utilizes voter and candidate characteristics, and therefore could be applied to predict the results of any campaign before it even begins. (The primary assumption here is that individual voters behave in a consistent way but vote differently from election to election as they are presented with different inputs to their decision-making calculus.) We hope the value of this is obvious.
Now, on to the results! The final predictions of all organizations and the actual results were as follows:
To start with, our predictions included many more close races than the others: while we predicted average margins of victory of about 10 points, the others were predicting averages well above that (ranging from around 25 to 30 points). The actual results fell in between at around 20 points.
Looking at specific races, we did better than the others at predicting close races in York Centre and Parkdale-High Park, where the majority predicted strong Liberal wins. Further, while everyone was wrong in Toronto-Danforth (which went Liberal by only around 1,000 votes), we predicted the smallest margin of victory for the NDP. On top of that, we were as good as the others in six ridings, meaning that we were at least as good as poll tracking in 9 out of 25 ridings (and would have been 79 days ago, before the campaign started, despite the polls changing up until the day before the election).
But that means we did worse in the others ridings, particularly Toronto Centre (where our model was way off), and a handful of races that the model said would be close but ended up being strong Liberal wins. While we need to undertake much more detailed analysis (once Elections Canada releases such details), the “surprise” in many of these cases was the extent to which voters, who might normally vote NDP, chose to vote Liberal this time around (likely a coalescence of “anti-Harper” sentiment).
Overall, we are pleased with how the model stood up, and know that we have more work to do to improve our accuracy. This will include more data and more variables that influence voters’ decisions. Thankfully, we now have a few years before the next election…
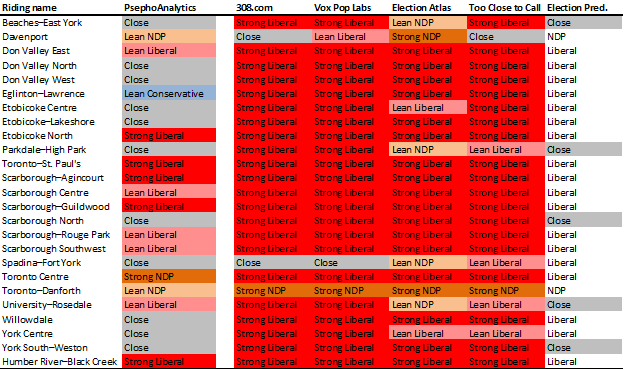
Well, it is now only days until the 42nd Canadian election, and we have come a long way since this long campaign started. Based on our analyses to date of voter and candidate characteristics, we can now provide riding-level predictions. As we keep saying, we have avoided the use of polls, so these present more of an experiment than anything else. Nonetheless, we’ve put them beside the predictions of five other organizations (as of the afternoon of 15 October 2015), specifically:
(We’ll note that the last doesn’t provide the likelihood of a win, so isn’t colour-coded below, but does provide additional information for our purposes here.)
You’ll see that we’re predicting more close races than all the others combined, and more “leaning” races. In fact, the average margin of victory from 308, Vox Pop, and Too Close to Call are 23%/26%/23% respectively, which sounds high. Nonetheless, the two truly notable differences we’re predicting are in Eglinton-Lawrence, where the consensus is that finance minister Joe Oliver will lose badly (we predict he might win) and Toronto Centre, where Bill Munro is predicted to easily beat Linda McQuaig (we predict the opposite).
Anyway, we’re excited to see how these predictions look come Monday, and we’ll come back after the election with an analysis of our performance.
We’ve started looking into what might be a natural cycle between governing parties, which may account for some of our differences to the polls that we’ve seen. The terminology often heard is “time for a change” – and this sentiment, while very difficult to include in voter characteristics, is possible to model as a high level risk to governing parties.
To start, we reran our predictions with an incumbent-year interaction, to see if the incumbency bonus changed over time. Turns out it does – incumbency effect declines over time. But it is difficult to determine, from only a few years of data, whether we’re simply seeing a reversion to the mean. So we need more data – and likely at a higher level.
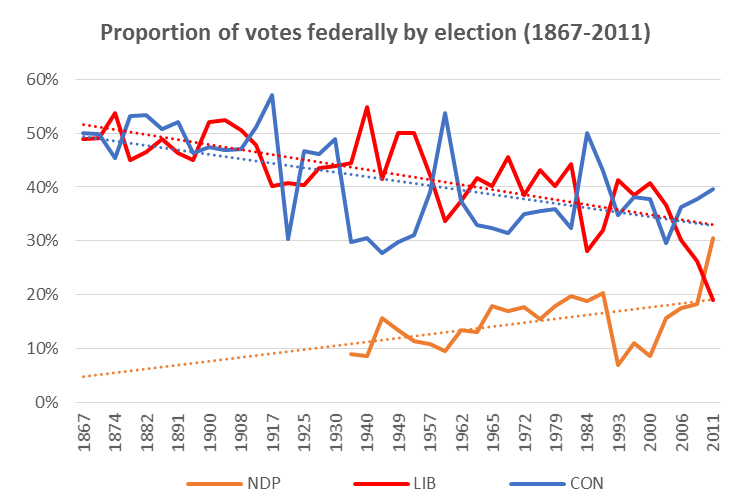
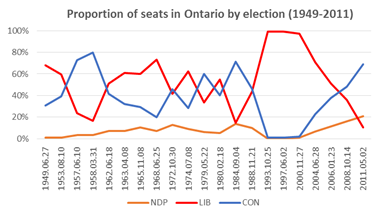
Let’s start with the proportion of votes received by each of today’s three major parties (or their predecessors – whose names we’ll simply substitute with modern party names), with trend lines, in every federal election since Confederation:
This chart shows that the Liberal & Conservative trend lines are essentially the same, and that the two parties effectively cycle as the governing party over this line.
Prior to a noticeable 3rd party (i.e., the NDP starting in the 1962 election and its predecessor Co-operative Commonwealth Federation starting in the 1935 election) the Liberals and Conservatives effectively flipped back and forth in terms of governing (6 times over 68 years), averaging around 48% of the vote each. Since then, the flip has continued (10 more times over the following 80 years), and the median proportion of votes for Liberals, Conservatives, and NDP has been 41%/35%/16% respectively.
Further, since 1962, the Liberals have been very slowly losing support (about 0.25 points per election), while the other two parties have been very slowly gaining it (about 0.05 points per election), though there has been considerable variation across each election, making this slightly harder to use in predictions. (We’ll look into including this in our risk modeling).
Next, we looked at some stats about governing:
In the 148.4 years since Sir John A. Macdonald was first sworn in, there have been 27 PM-ships (though only 22 PMs), for an average length of 5.5 years (though 4.3 years for Conservatives and 6.9 years for Liberals).
Parties often string a couple PMs together - so the PM-ship has only switched parties 16 times with an average length of 8.7 years (or 7.2 Cons vs. 10.4 Libs).
Only two PMs have won four consecutive elections (Macdonald and Laurier), with four more having won three (Mackensie King, Diefenbaker, Trudeau, and Crétien) prior to Harper.
All of these stats would suggest that Harper is due for a loss: he has been the sole PM for his party for 9.7 years, which is over twice his party’s average length for a PM-ship. He’s also second all-time behind Macdonald in a consecutive Conservative PM role (having past Mulroney and Borden last year). From a risk-model perspective, Harper is likely about to become hit hard by the “time for a change” narrative.
But how much will this actually affect Conservative results? And how much will their opponents benefit? These are critical questions to our predictions.
In any election where the governing party lost (averaging once every 9 years; though 7 years for Conservatives, and 11 years for Liberals), that party saw a median drop of 6.1 points from the preceding election (average of 8.1 points). Since 1962 (first election with the NDP), that loss has been 5.5 points. But do any of those votes go to the NDP? Turns out, not really: those 5.5 points appear to (at least on average) switch back to the new governing party.
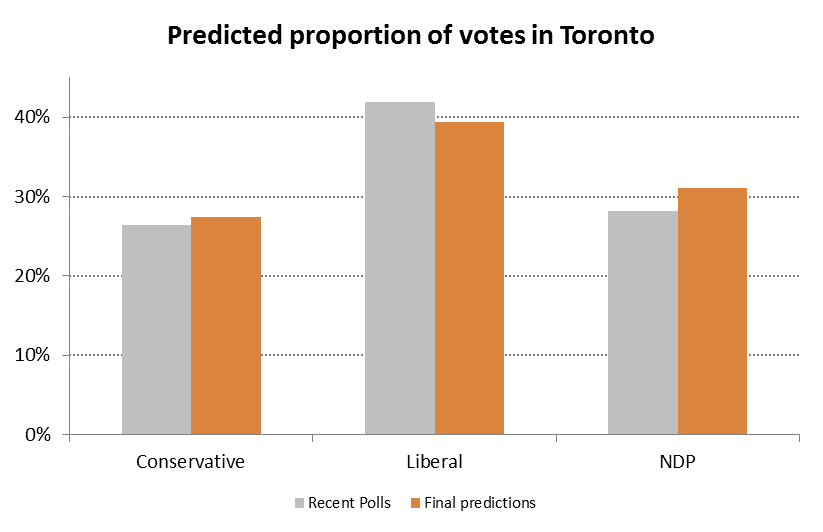
Given the risk to the current governing party, we would forecast a 5.5%-6.1% shift from the Conservatives to the Liberals, on top of all our other estimates (which would not overlap with any of this analysis), assuming that Toronto would feel the same about change as the rest of the country has historically.
That would mean our comparisons to recent Toronto-specific polls would look like this:
Remember – our analysis has avoided the use of polls, so these results (assuming the polls are right) are quite impressive.
Next up (and last before the election on Monday) will be our riding-level predictions.
Political psychologists have long held that over-simplified “rational” models of voters do not help accurately predict their actual behavior. What most behavioural researchers have found is the decision-making (e.g., voting) often boils down to emotional, unconscious factors. So, in attempting to build up our voting agents, we will need to at least:
include multiple issue perspectives, not just a simple evaluation of “left-right”;
include data for non-policy factors that could determine voting; and
not prescribe values to our agents beyond what we can empirically derive.
Given that we are unable to peek into voters’ minds (and remember: we are trying to avoid using polls[1]), we need data for (or proxies for) factors that might influence someone’s vote. So, we gathered (or created) and joined detailed data for the 2006, 2008, and 2011 Canadian federal elections (as well as the 2015 election, which will be used for predictions).
In a new paper, we discuss what influence multiple factors, such as “leader likeability”, incumbency, “star” status, demographics and policy platforms, may have on voting outcomes, and use these results to predict the upcoming federal election in Toronto ridings.
At a high-level, we find that:
Almost all variables are statistically significant.
Being either a star candidate or an incumbent can boost a candidates share of the vote by 21%, but being both an incumbent and a star candidate does not give a candidate an incremental increase. The two effects are equivalent to belonging to a party (21%).
Leader likeability is associated with a 0.3% change in the proportion of votes received by a candidate. So, a leader that essentially polls the same as their party yields their Toronto-based candidates about 14 points.
The relationships between age, gender, family income, and the proportion of votes vary widely across the parties (as expected). For example, family income tends to increase support for Conservatives (0.005/$10,000) while decreasing for the other two major parties by roughly the same magnitude.
Policy matters, but only slightly, and only economic and environmental issues overall.
With our empirical results, we can turn to predicting the 2015 federal election in Toronto ridings.
It turns out that our Toronto-wide results are fairly in line with recent Toronto-specific polling results (weighted by age and sample size) – though we’ll see how right we all are come election day – which means that there may some inherent truth in the coefficients we have found.
Given that we haven’t used polls or included localized details or party platforms, these results are surprisingly good. The seeming shift from Liberal to Conservative is something that we’ll need to look into further. It is likely highlighting an issue with our data: namely, that we only have three years of detailed federal elections data, and these elections have seen some of the best showings for the Conservatives (and their predecessors) in Ontario since the end of the second world war (the exceptions being in the late 1950s with Diefenbaker, 1979 with Joe Clark, and 1984 with Brian Mulroney), with some of the worst for the Liberals over the same time frame. That is, we are not picking up a (cyclical) reversion to the mean in our variables, but might investigate the cycle itself.
Nonetheless, given we set out to understand (both theoretically and empirically) how to predict an election while significantly limiting the use of polls, and it appears that we are at least on the right track.
[1] This is true for a number of reasons: first, we want to be able to simulate elections, and therefore would not always have access to polls; second, we are trying to do something fundamentally different by observing behaviour instead of asking people questions, which often leads to lying (e.g., social desirability biases: see the “Bradley effect”); third, while polls in aggregate are generally good at predicting outcomes, individual polls are highly volatile.
Given that we are unable to peek into voters’ minds (remember: we are trying to avoid using polls as much as possible), we need data (or proxies) for factors that might influence someone’s vote. We gathered (or created) and joined data for the 2006, 2008, and 2011 Canadian federal elections (as well as the 2015 election, which will be used for predictions) for Toronto ridings.
We’ll be explaining all this in more detail next week, but for now, here are some basics:
We’ve assigned leader “likeability” scores to the major party leaders in each election, using polls that ask questions about leadership characteristics and formulaically compare them to party-level polls around the same time. This provides a value for (or at least a proxy of) how much influence the party leader was having on their party’s showing in the polls, and should account for much of the party variation that we see from year to year. (We also use party identifiers, to identify a “base”.)
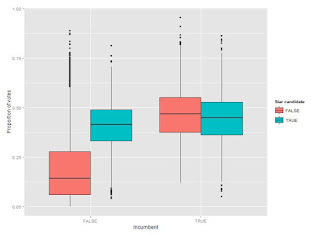
For all 366 candidates across the three elections, we identify two things: are they an incumbent, and are they a “star” candidate, by which we mean would they be generally known outside of their riding? This yields 64 candidate-year incumbents (i.e., an individual could be an incumbent in all three elections) and 29 candidate-year stars.
Regressing these data against the proportion of votes received across ridings yields some interesting results. First: party, leader likeability, star candidate, and incumbency are all statistically significant (as is the interaction of star candidate and incumbency). This isn’t a surprise, given the literature around what it is that drives voters’ decisions. (Note that we haven’t yet included demographics or party platforms.)
Breaking down the results: Being a star candidate or an incumbent (but not both) adds about 20 points right off the top, so name recognition obviously matters a lot. Likeability matter too; a leader that essentially polls the same as their party yields candidates about 14 points. (As an example of what this means, Stephane Dion lost the average Liberal candidate in Toronto about 9 points relative to Paul Martin. Alternatively, in 2011, Jack Layton added about 16 points more to NDP candidates in Toronto than Michael Ignatieff did for equivalent Liberal candidates.) Finally, party base matters too: for example, being an average Liberal candidate in Toronto adds about 17 points over the equivalent NDP candidate. (We expect some of this will be explained with demographics and party platforms.)
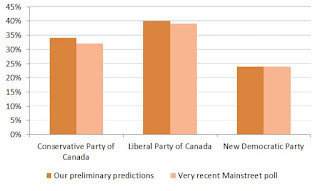
To be clear, these are average results, so we can’t yet use them effectively for predicting individual riding-level races (that will come later). But, if we apply them to all 2015 races in Toronto and aggregate across the city, we would predict voting proportions very similar to the results of a recent poll by Mainstreet (if undecided voters split proportionally):
Given that we haven’t used polls or included localized details or party platforms, these results are amazing, and give us a lot of confidence that we’re making fantastic progress in understanding voter behaviour (at least in Toronto).
Analyzing the upcoming federal election requires collecting and integrating new data. This is often the most challenging part of any analysis and we’ve committed significant efforts to obtaining good data for federal elections in Toronto’s electoral districts.
Clearly, the first place to start was with Elections Canada and the results of previous general elections. These are available for download as collections of Excel files, which aren’t the most convenient format. So, our toVotes package has been updated to include results from the 2006, 2008, and 2011 federal elections for electoral districts in Toronto. The toFederalVotes data frame provides the candidate’s name, party, whether they were an incumbent, and the number of votes they received by electoral district and poll number. Across the three elections, this amounts to 82,314 observations.
Connecting these voting data with other characteristics requires knowing where each electoral district and poll are in Toronto. So, we created spatial joins among datasets to integrate them (e.g., combining demographics from census data with the vote results). Shapefiles for each of the three federal elections are available for download, but the location identifiers aren’t a clean match between the Excel and shapefiles. Thanks to some help from Elections Canada, we were able to translate the location identifiers and join the voting data to the election shapefiles. This gives us close to 4,000 poll locations across 23 electoral districts in each year. We then used the census shapefiles to aggregate these voting data into 579 census tracts. These tracts are relatively stable and give us a common geographical classification for all of our data.
This work is currently in the experimental fed-geo branch of the toVotes package and will be pulled into the main branch soon. Now, with votes aggregated into census tracts, we can use the census data for Toronto in our toCensus package to explore how demographics affect voting outcomes.
Getting the data to this point was more work than we expected, but well worth the effort. We’re excited to see what we can learn from these data and look forward to sharing the results with you.
A number of people have been asking whether we are going to analyze the upcoming federal election on October 19, like we did for the Toronto mayoral race last year. The truth is, we never stopped working after the mayoral race, but are back with a vengeance for the next five weeks.
We have gathered tonnes of new data and refined our methodology. We have also established a new domain name: psephoanalytics.ca. You can still subscribe to email updates here, or follow us on twitter @psephoanalytics. Finally, if you’d like to chat directly, please email us psephoanalytics@gmail.com.
Nonetheless, stay tuned for lots of updates over the coming weeks, culminating in some predictions for Toronto ridings prior to October 19.
The first (and long) step in moving towards agent-based modeling is the creation of the agents themselves. While fictional, they must represent reality – meaning they need to behave like actual people. The main issue in voter modeling, however, is that since voting is private we do not know how individuals behave, only collections of voters – and we do not want them all to behave the exact same way. That is why one of the key elements of our work is the ability to create meaningful differences among our agents – particularly when it comes to the likes of issue positions and political engagement.
The obvious difficulty is how to do that. In our model, many of our agents’ characteristics are limited to values between 0 and 1 (e.g., political positions, weights on given issues). Many standard distributions, such as the normal, would be cut off at these extremes, creating unrealistic “spikes” of extreme behaviour. We also cannot use uniform distributions, as the likelihood of individuals in a group looking somewhat the same (i.e., more around an average) seems much more reasonable than them looking uniformly different.
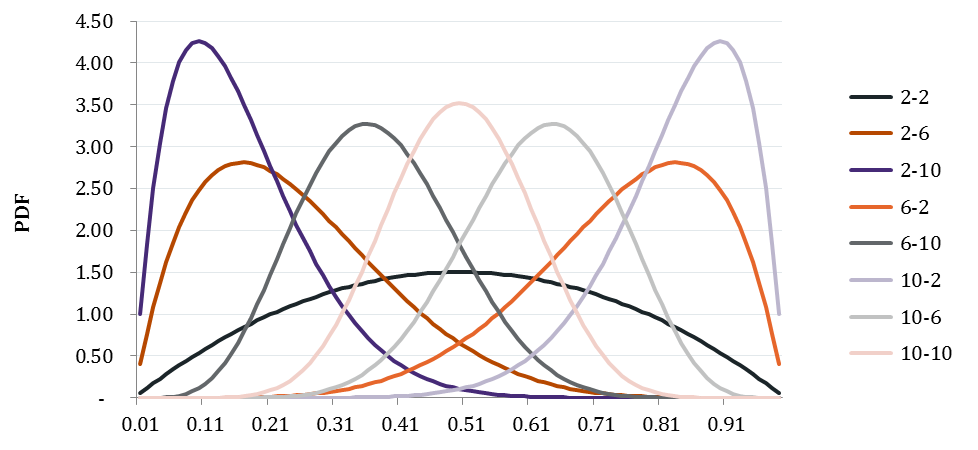
Which brings us to the β distribution. In a new paper, we discuss applying this family of distributions to voter characteristics. While there is great diversity in the potential shapes of these distributions - granting us the flexibility we need - in (likely) very extreme cases, the shape will not “look like” what we would expect. Therefore, one of our goals will be to somewhat constrain our selection of fixed values for α and β, based on as much empirical data as possible, to ensure we get this balance right.
A selection α-β combinations that generate “useful” distributions:
As the next Federal General Election gets closer, we’re turning our analytical attention to how the election might play out in Toronto. The first step, of course, is to gather data on prior elections. So, we’ve updated our toVotes data package to include the results of the 2008 and 2011 federal elections for electoral districts in Toronto.
This dataset includes the votes received by each candidate in each district and poll in Toronto. We also include the party affiliation of the candidate and whether they are an incumbent. These data are currently stored in a separate dataset from the mayoral results, since the geography of the electoral districts and wards aren’t directly comparable. We’ll work on integrating these datasets more closely and adding in further election results over the coming weeks.
Hopefully the general availability of cleaned and integrated datasets, such as this one, will help generate more analytically-based discussions of the upcoming election.
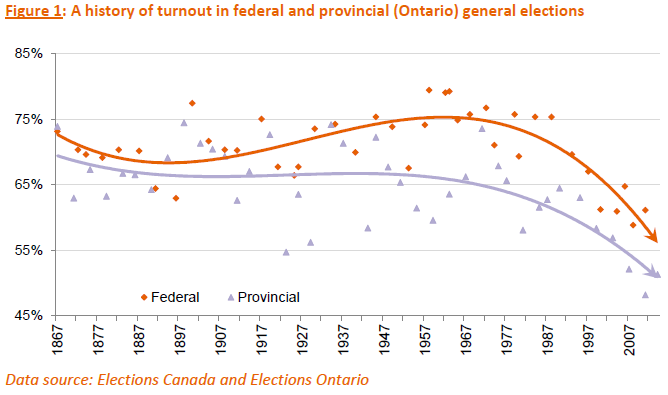
Turnout is often seen as (at least an easy) metric of the health of a democracy – as voting is a primary activity in civic engagement. However, turnout rates continue to decline across many jurisdictions[i]. This is certainly true in Canada and Ontario.
From the PsephoAnalytics perspective – namely, accurately predicting the results of elections (particularly when using an agent-based model (ABM) approach) – requires understanding what it is that drives the decision to vote at all, instead of simply staying home.
If this can be done, we would not only improve our estimates in an empirical (or at least heuristic) way, but might also be able to make normative statements about elections. That is, we hope to be able to suggest ways in which turnout could be improved, and whether (or how much) that mattered.
In a new paper we start to investigate the history of turnout in Canada and Ontario, and review what the literature says about the factors associated with turnout, in an effort to help “teach” our agents when and why they “want” to vote. More work will certainly be required here, but this provides a very good start.
We value constructive feedback and continuous improvement, so we’ve taken a careful look at how our predictions held up for the recent mayoral election in Toronto.
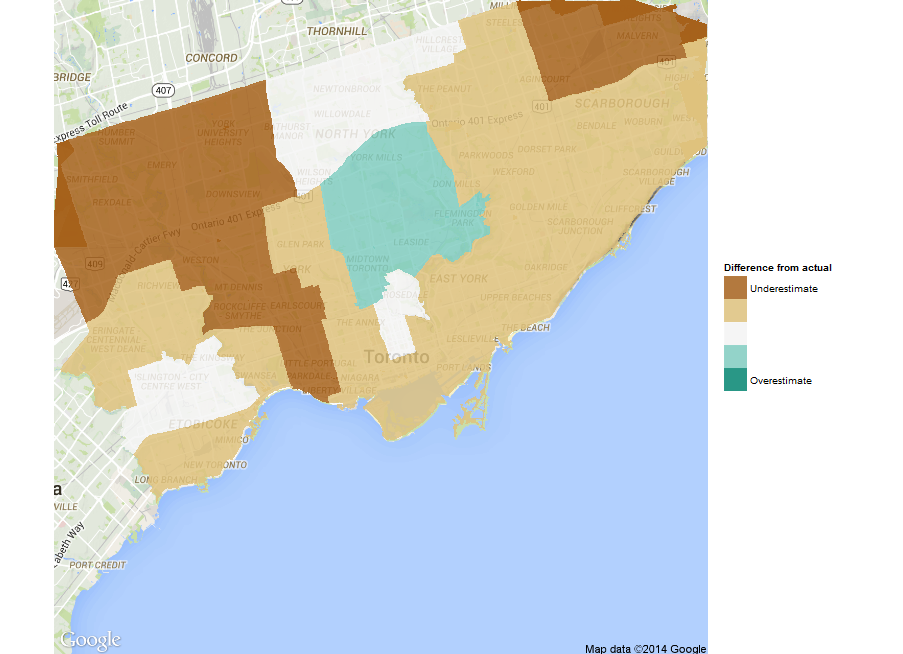
The full analysis is here. The summary is that our estimates weren’t too bad on average: the distribution of errors is centered on zero (i.e., not biased) with a small standard error. But, on-average estimates are not sufficient for the types of prediction we would like to make. At a ward-level, we find that we generally overestimated support for Tory, especially in areas where Ford received significant votes.
We understood that our simple agent-based approach wouldn’t be enough. Now we’re particularly motivated to gather up much more data to enrich our agents' behaviour and make better predictions.
The results are in, and our predictions performed reasonably well on average (we averaged 4% off per candidate). Ward by ward predictions were a little more mixed, though, with some wards being bang on (looking at Tory’s results), and some being way off – such as northern Scarborough and Etobicoke. (For what it’s worth, the polls were a ways off in this regard too.) This mostly comes down to our agents not being different enough from one another. We knew building the agents would be the hardest part, and we now have proof!
Regardless, we still think that the agent-based modeling approach is the most appropriate for this kind of work – but we obviously need a lot more data to teach our agents what they believe. So, we’re going to spend the next few months incorporating other datasets (e.g., historical federal and provincial elections, as well as councillor-level data from the 2014 Toronto election). The other piece that we need to focus on is turnout. We knew our turnout predictions were likely the minimum for this election, but aren’t yet able to model a more predictive metric, so we’ll be conducting a study into that as well.
Finally, we’ll provide detailed analysis of our predictions once all the detailed official results become available.
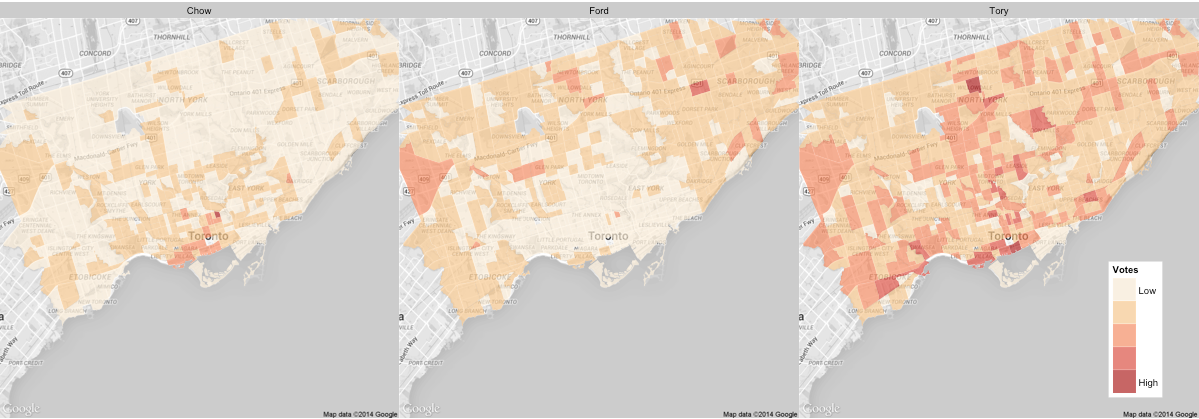
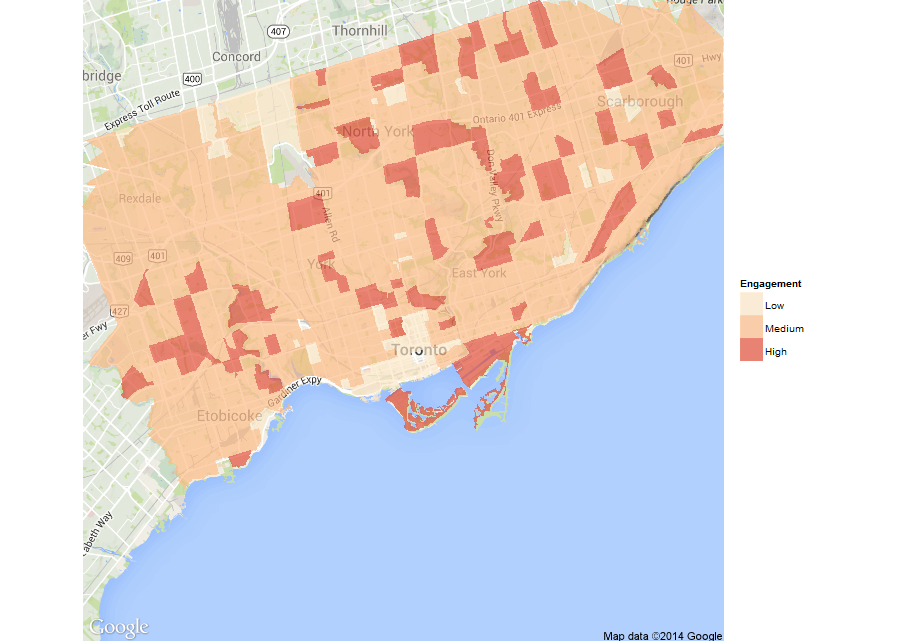
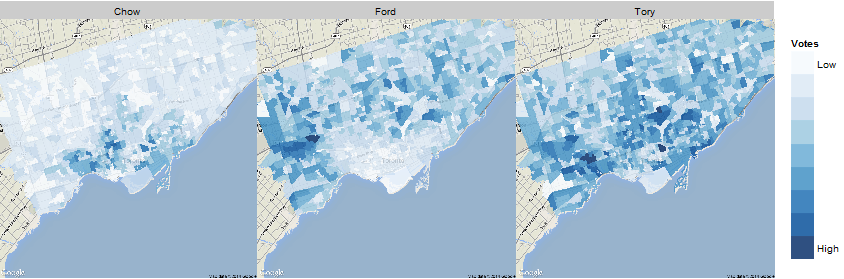
Our final predictions have John Tory winning the 2014 mayoral election in Toronto with a plurality 46% of the votes, followed by Doug Ford (29%) and Olivia Chow (25%). We also predict turnout of at least 49% across the city, but there are differences in turnout among each candidate’s supporters (with Tory’s supporters being the most likely to vote by a significant margin - which is why our results are more in his favour than recent polls). We predict support for each candidate will come from different pockets of the city, as can be seen on the map below.
These predictions were generated by simulating the election ten times, each time sampling one million of our representative voters (whom we created) for their voting preferences and whether they intend to vote.
Each representative voter has demographic characteristics (e.g., age, sex, income) in accordance with local census data, and lives in a specific ‘neighbourhood’ (i.e., census tract). These attributes helped us assign them political beliefs – and therefore preferences for candidates – as well as political engagement scores that come from various studies of historical turnout (from the likes of Elections Canada). The latter allows us to estimate the likelihood of each specific agent actually casting a ballot.
We’ll shortly also release a ward-by-ward summary of our predictions.
In the end, we hope this proof-of-concept proves to be a more refined (and therefore useful in the long-term) than polling data. As the model becomes more sophisticated, we’ll be able to do scenario testing and study other aspects of campaigns.
As promised, here is a ward-by-ward breakdown of our final predictions for the 2014 mayoral election in Toronto. We have Tory garnering the most votes in 33 wards for sure, plus likely another 5 in close races. Six wards are “too close to call”, with three barely leaning to Tory (38, 39, and 40) and three barely leaning to Ford (8, 35, and 43). We’re not predicting Chow will win in any ward, but will come second in fourteen.
The first (and long) step in moving towards agent-based modeling is the creation of the agents themselves. While fictional, they must be representative of reality – meaning they need to behave like actual people might.
In developing a proof of concept of our simulation platform (which we’ll lay out in some detail soon), we’ve created 10,000 agents, drawn randomly from the 542 census tracts (CTs) that make up Toronto per the 2011 Census, proportional to the actual population by age and sex. (CTs are roughly “neighbourhoods”.) So, for example, if 0.001% of the population of Toronto are male, aged 43, living in a CT on the Danforth, then roughly 0.001% of our agents will have those same characteristics. Once the basic agents are selected, we assign (for now) the median household income from the CT to the agent.
But what do these agents believe, politically? For that we take (again, for now) a weighted compilation of relatively recent polls (10 in total, having polled close to 15,000 people, since Doug Ford entered the race), averaged by age/sex /income group/region combinations (420 in total). These give us average support for each of the three major candidates (plus “other”) by agent type, which we then randomly sample (by proportion of support) and assign a Left-Right score (0-100) as we did in our other modeling.
This is somewhat akin to polling, except we’re (randomly) assigning these agents what they believe rather than asking, such that it aggregates back to what the polls are saying, on average.
Next, we take the results of an Elections Canada study on turnout by age/sex that allows us to similarly assign “engagement” scores to the agents. That is, we assign (for now) the average turnout by age/sex group accordingly to each agent. This gives us a sense of likely turnout by CT (see map below).
There is much more to go here, but this forms the basis of our “voter” agents. Next, we’ll turn to “candidate” agents, and then on to “media” agents.
Our most recent analysis shows Tory still in the lead with 44% of the votes, followed by Doug Ford at 33% and Olivia Chow at 23%.
Our analytical approach allows us to take a closer, geographical look. Based on this, we see general support for Tory across the city, while Ford and Chow have more distinct areas of support.
This still based on our original macro-level analysis, but gives a good sense of where our agents support would be (on average) at a local level.
Given the caveats we outlined re: macro-level voting modeling, we’re moving on to a totally different approach. Using something called agent-based modeling (ABM), we’re hoping to move to a point where we can both predict elections, but also use the system to conduct studies on the effectiveness of various election models.
ABM can be defined simply as an individual-centric approach to model design, and has become widespread in multiple fields, from biology to economics. In such models, researchers define agents (e.g., voters, candidates, and media) each with various properties, and an environment in which such agents can behave and interact.
Examining systems through ABM seeks to answer four questions:
Empirical: What are the (causal) explanations for how systems evolve?
Heuristic: What are outcomes of (even simple) shocks to the system?
Method: How can we advance our understanding of the system?
Normative: How can systems be designed better?
We’ll start to provide updates on our progress on the development on our system in the coming weeks.
Based on updated poll numbers (per Threehundredeight.com as of September 16) - where John Tory has a commanding lead - we’re predicting that the wards to watch in the upcoming Toronto mayoral election are clustered in two areas, surprisingly, traditional strongholds for Doug Ford and Olivia Chow.
The first set are Etobicoke North & Centre (wards 1-4), traditional Ford territory. The second are in the south-west portion of downtown, traditional NDP territory, specifically Parkdale-High Park, Davenport, Trinity-Spadina (x2), and Toronto Danforth (respectively wards 14, 18-20, and 30).
As the election gets closer, we’ll provide more detailed predictions.
As with any analytical project, we invested significant time in obtaining and integrating data for our neighbourhood-level modeling. The Toronto Open Data portal provides detailed election results for the 2003, 2006, and 2010 elections, which is a great resource. But, they are saved as Excel files with a separate worksheet for each ward. This is not an ideal format for working with R.
We’ve taken the Excel files for the mayoral-race results and converted them into a data package for R called toVotes. This package includes the votes received by ward and area for each mayoral candidate in each of the last three elections.
If you’re interested in analyzing Toronto’s elections, we hope you find this package useful. We’re also happy to take suggestions (or code contributions) on the GitHub page.
In our first paper, we describe the results of some initial modeling - at a neighbourhood level - of which candidates voters are likely to support in the 2014 Toronto mayoral race. All of our data is based upon publicly available sources.
We use a combination of proximity voter theory and statistical techniques (linear regression and principal-component analyses) to undertake two streams of analysis:
Determining what issues have historically driven votes and what positions neighbourhoods have taken on those issues
Determining which neighbourhood characteristics might explain why people favour certain candidates
In both cases we use candidates’ currently stated positions on issues and assign them scores from 0 (‘extreme left’) to 100 (‘extreme right’). While certainly subjective, there is at least internal consistency to such modeling.
This work demonstrates that significant insights on the upcoming mayoral election in Toronto can be obtained from an analysis of publicly available data. In particular, we find that:
Voters will change their minds in response to issues. So, “getting out the vote” is not a sufficient strategy. Carefully chosen positions and persuasion are also important.
Despite this, the ‘voteability’ of candidates is clearly important, which includes voter’s assessments of a candidate’s ability to lead and how well they know the candidate’s positions.
The airport expansion and transportation have been the dominant issues across the city in the last three elections, though they may not be in 2014.
A combination of family size, mode of commuting, and home values (at the neighbourhood level) can partially predict voting patterns.
We are now moving on to something completely different, where we use an agent-based approach to simulate entire elections. We are actively working on this now and hope to share our progress soon.
Political campaigns have limited resources -–both time and financial - that should be spent on attracting voters that are more likely to support their candidates. Identifying these voters can be critical to the success of a candidate.
Given the privacy of voting and the lack of useful surveys, there are few options for identifying individual voter preferences:
Polling, which is large-scale, but does not identify individual voters
Voter databases, which identify individual voters, but are typically very small scale
In-depth analytical modeling, which is both large-scale and helps to ‘identify’ voters (at least at a neighbourhood level on average)
The goal of PsephoAnalytics* is to model voting behaviour in order to accurately explain campaigns (starting with the 2014 Toronto mayoral race). This means attempting to answer four key questions:
What are the (causal) explanations for how election campaigns evolve – and how well can we predict their outcomes?
What are effects of (even simple) shocks to election campaigns?
How can we advance our understanding of election campaigns?
How can elections be better designed?
Psephology (from the Greek psephos, for ‘pebble’, which the ancient Greeks used as ballots) deals with the analysis of elections.
I recently participated in a panel discussion at the University of Toronto on the career transition from academic research to public service. I really enjoyed the discussion and there were many great questions from the audience. Here’s just a brief summary of some of the main points I tried to make about the differences between academics and public service.
The major difference I’ve experienced involves a trade-off between control and influence.
As a grad student and post-doctoral researcher I had almost complete control over my work. I could decide what was interesting, how to pursue questions, who to talk to, and when to work on specific components of my research. I believe that I made some importantcontributions to my field of study. But, to be honest, this work had very little influence beyond a small group of colleagues who are also interested in the evolution of floral form.
Now I want to be clear about this: in no way should this be interpreted to mean that scientific research is not important. This is how scientific progress is made – many scientists working on particular, specific questions that are aggregated into general knowledge. This work is important and deserves support. Plus, it was incredibly interesting and rewarding.
However, the comparison of the influence of my academic research with my work on infrastructure policy is revealing. Roads, bridges, transit, hospitals, schools, courthouses, and jails all have significant impacts on the day-to-day experience of millions of people. Every day I am involved in decisions that determine where, when, and how the government will invest scarce resources into these important services.
Of course, this is where the control-influence trade-off kicks in. As an individual public servant, I have very little control over these decisions or how my work will be used. Almost everything I do involves medium-sized teams with members from many departments and ministries. This requires extensive collaboration, often under very tight time constraints with high profile outcomes.
For example, in my first week as a public servant I started a year-long process to integrate and enhance decision-making processes across 20 ministries and 2 agencies. The project team included engineers, policy analysts, accountants, lawyers, economists, and external consultants from all of the major government sectors. The (rather long) document produced by this process is now used to inform every infrastructure decision made by the province.
Governments contend with really interesting and complicated problems that no one else can or will consider. Businesses generally take on the easy and profitable issues, while NGOs are able to focus on specific aspects of issues. Consequently, working on government policy provides a seemingly endless supply of challenges and puzzles to solve, or at least mitigate. I find this very rewarding.
None of this is to suggest that either option is better than the other. I’ve been lucky to have had two very interesting careers so far, which have been at the opposite ends of this control-influence trade-off. Nonetheless, my experience suggests that an actual academic career is incredibly challenging to obtain and may require significant compromises. Public service can offer many of the same intellectual challenges with better job prospects and work-life balance. But, you need to be comfortable with the diminished control.
Thanks to my colleague Andrew Miller for creating the panel and inviting me to participate. The experience led me to think more clearly about my career choices and I think the panel was helpful to some University of Toronto grad students.
Our offices will be moving to this new space. I’m looking forward to actually working in a green building, in addition to developing green building policies.
The Jarvis Street project will set the benchmark for how the province manages its own building retrofits. The eight-month-old Green Energy Act requires Ontario government and broader public-sector buildings to meet a minimum LEED Silver standard – Leadership in Energy and Environmental Design. Jarvis Street will also be used to promote an internal culture of conservation, and to demonstrate the province’s commitment to technologically advanced workspaces that are accessible, flexible and that foster staff collaboration and creativity, Ms. Robinson explains.
I spend a fair bit of time with a locked-down Windows XP machine. Fortunately, I’m able to install Emacs which provides capabilities that I find quite helpful. I’ve had to reinstall Emacs a few times now. So, for my own benefit (and perhaps your’s) here are the steps I follow:
Download EmacsW32 patched and install in my user directory under Apps
The CaGBC maintains a list of all the registered LEED projects in Canada. This is a great resource, but rather awkward for analyses. I’ve copied these data into a DabbleDB application with some of the maps and tabulations that I frequently need to reference.
Here for example is a map of the density of LEED projects in each province. While here is a rather detailed view of the kinds of projects across provinces. There are several other views available. Are there any others that might be useful?
I was given an opportunity to propose a measure to clarify how and on what basis the federal government allocates funds to STI - a measure that would strengthen relations between the federal government and the STI community by eliminating misunderstandings and suspicions on this point. In short, my proposal was that Ottawa direct its Science, Technology and Innovation Council to do three things:
To provide an up-to-date description of how these allocation decisions have been made in the past;
To identify the principles and sources of advice on which such decisions should be based;
To recommend the most appropriate structure and process - one characterized by transparency and openness - for making these decisions in the future.
These are reasonable suggestions from Preston Manning: be clear about why and how the Federal government funds science and technology.
Of course I may not agree with the actual decisions made through such a process, but at least I would know why the decisions were made. The current process is far too opaque and confused for such critical investment decisions.