Day 13: Lucy is a couch animal 📷

Day 13: Lucy is a couch animal 📷
Day 12: Rock legends 📷

Day 11: Hygge 📷

Statistics Canada has a wealth of data that are essential for good public policy. Often a good third of my analytical scripts are devoted to accessing and processing data from the Statistics Canada website, which always seems like a waste of effort and good opportunity for making silly errors. So, I was keen to test out the cansimpackage for R to see how it might help. The quick answer is “very much”.
The documentation for the cansim package is thorough and doesn’t need to be repeated here. I thought it might be useful to illustrate how helpful the package can be by refactoring some earlier work that explored consumer price inflation.
These scripts always start off with downloading and extracting the relevant data file:
cpi_url <- "https://www150.statcan.gc.ca/n1/tbl/csv/18100004-eng.zip" # (1)
if(file.exists("18100004-eng.zip")) { # (2)
# Already downloaded
} else {
download.file(cpi_url,
destfile = "18100004-eng.zip",
quiet = TRUE)
unzip("18100004-eng.zip") # (3)
}
cpi <- readr::read_csv("18100004.csv") # (4)
A few things to note here:
readr package imports the final csv fileWith cansim all I need to know is the data series number:
cansim_table <- "18-10-0004"
cpi <- cansim::get_cansim(cansim_table)
get_cansimdownloads the right file to a temporary directory, extracts the data, and imports it as a tidyverse-compatible data frame.
The get_cansim function has some other nice features. It automatically creates a Date column with the right type, inferred from the standard REF_DATE column. And, it also creates a val_norm column that intelligently converts the VALUE column. For example, converting percentage or thousand-dollar values into standard formats.
The cansim package is a great example of a really helpful utility package that allows me to focus on analysis, rather than fiddling around with data. Definitely worth checking out if you deal with data from Statistics Canada.
Day 10: The bridges of my morning run 📷 🏃♂️






Day 9: Swinging through the trees is safe with this gear on 📷

Day 8: A benefit of a twilight run is that the sidewalks are clear 📷

Day 7: Spice 📷

Day 6: Street 📷

Day 5: The toys are watching, always 📷


Although A Desolation Called Peace by Arkady Martine isn’t as remarkable as A Memory Called Empire, I still really enjoyed it. Some of the enjoyment was momentum from the first book. I also liked the mystery of the aliens and the exploration of shared memories and awareness 📚
Day 4: Sharp dressed boy 📷

Day 3: Majority votes are rare in Canada these days 📷

Added this to my “brains are fascinating” note: How memories persist where bodies, and even brains, do not
It seems that a 44-year-old French man had gone to hospital complaining of a mild weakness in his left leg. Doctors learned that the patient ‘had a shunt inserted into his head to drain away hydrocephalus – water on the brain – as an infant. The shunt was removed when he was 14.’ When they scanned his brain, they found a huge fluid-filled chamber occupying most of the space in his skull, leaving little more than a thin sheet of actual brain tissue. The patient, a married father of two children, worked as a civil servant apparently leading a normal life, despite having a cranium filled with spinal fluid and very little brain tissue.
Day 2: Lightning up the Dark 📷

Day 1: Touch 📷


Fathoms by Rebecca Giggs is about so much more than whales. Beautifully written, Giggs uses whales to talk through society, culture, environmentalism, evolution, and history, along with lots of good natural history on whales📚
We had fun solving CluedUpp Games The Ripper mystery with these serious looking investigators

I really enjoyed the Foundation books as a kid and thought it might be fun to read them along with the new Apple TV show. I know they’ll diverge and look forward to seeing how they approach the original content

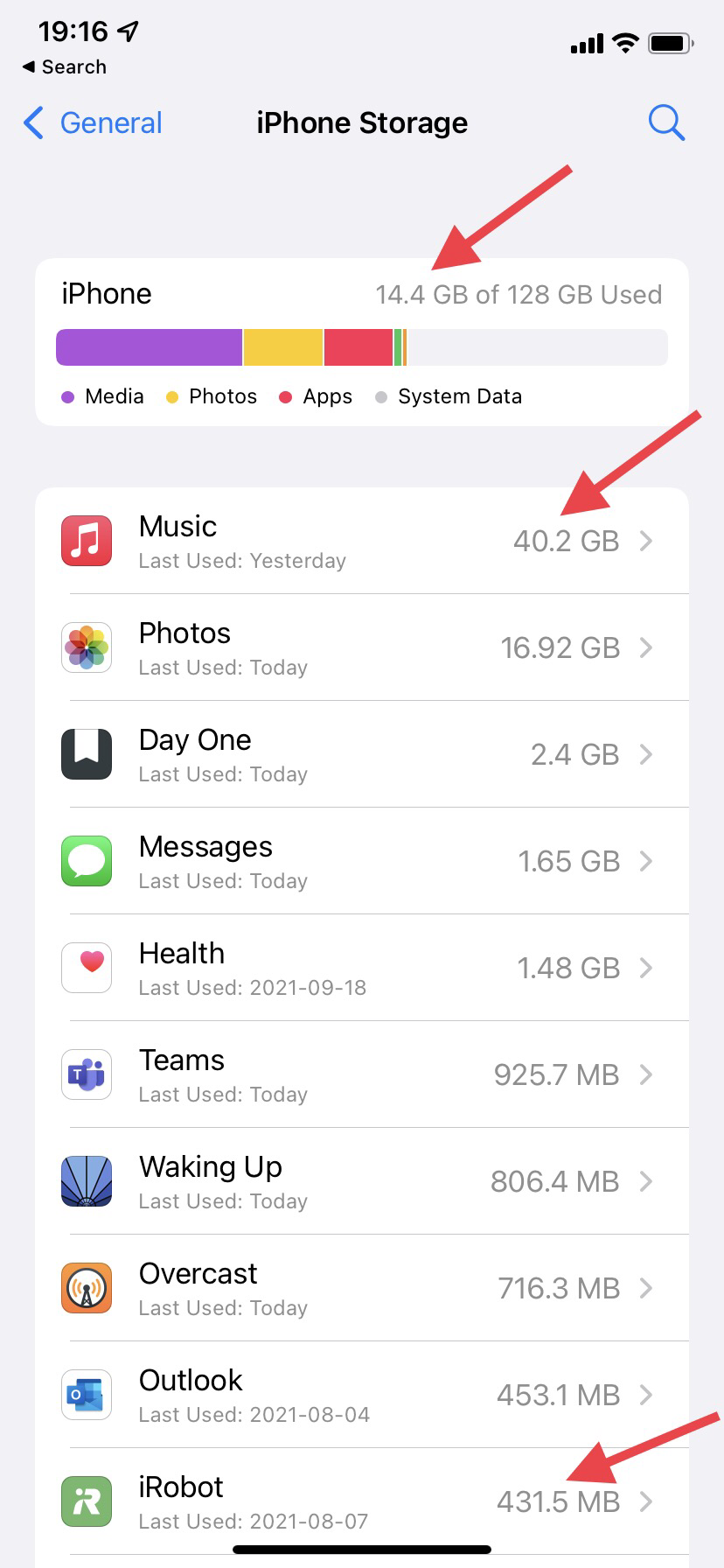
Two things to note: 1) Clearly the totalling is off and 2) How can the app for my robot vacuum be in the top 10?