Perhaps moral philosophers can contribute to public discourse even now—for instance, in thinking about how decisions should be made given the tremendous uncertainty involved, or to insist on the relevance of some neglected considerations. Or perhaps we should confess that we, too, are embarrassed, that we cannot be confident just what to say. Depending on your expectations, this may be disappointing. But unlike many of the other interventions in today’s public discourse, such a response would at least be honest. And probably less harmful as well.
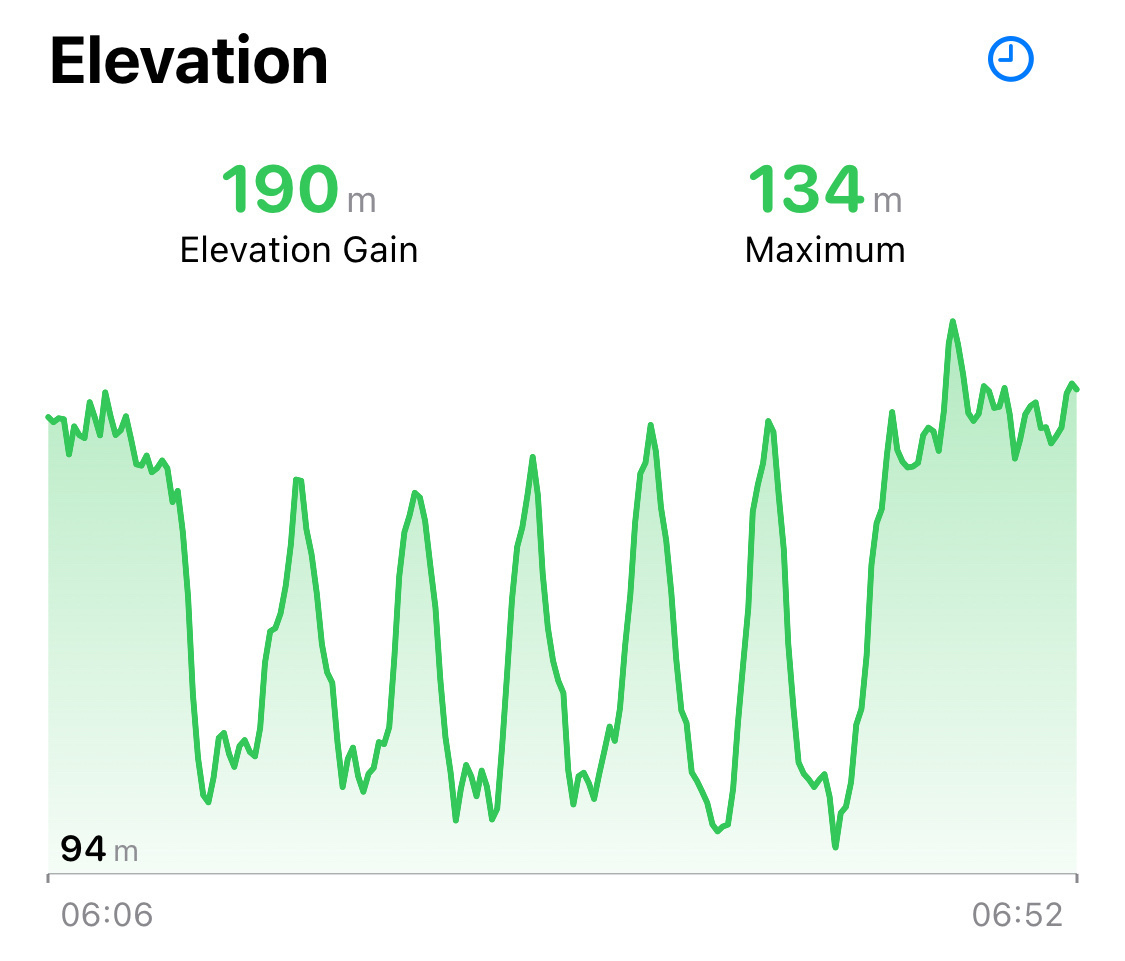
🏃♂️ Hill repeats at a steady, moderate pace for today’s run. I tried to focus on my downhill form: staying loose and keeping ground contact time short
Finished reading: American Moonshot by Douglas Brinkley. I’ve read several books about the Apollo missions, all of them focused on the science and engineering. This book is a fascinating look at the politics and JFK’s indispensable leadership. 🚀📚
Here’s my list. I’ve really shifted to defaults over the past year. I’m conflicted about this: I really like a good indie app, yet find my needs don’t justify the complexity of using non-defaults.
A good show. I binge-watched it over the weekend while recovering from a nasty cold. Hiddleston and Laurie are both great
Finished reading: The Alloy of Law by Brandon Sanderson is fun. A nice break from the epic storytelling of the previous series. The Sherlock Holmes meets Western lawman vibe fits in well with the allomancy 📚
Finished reading: Eyes of the Void by Adrian Tchaikovsky continues a great series. Interesting and diverse aliens, cosmic scale mysteries, and against all odds, plucky humans 📚
New running shoe day! After 1,109 kms, I’m replacing the orange ones with another pair of Saucony Kinvara. I definitely don’t recommend waiting so long, just got distracted 🏃♂️
There’s a bewildering array of fitness apps out there. Here’s an attempt to document what I’m currently using.
I have some criteria when considering a fitness app:
Available on the Apple Watch, ideally as a first class app, rather than just presenting data from the phone
Suitable for multisport. I’ll consider a highly specialized app, though prefer one that covers at least running, cycling, and swimming
Consolidated and local data. I prefer one location for all of the data and certainly not locked into a web service
With these in mind, my current portfolio of fitness apps is:
Apple Health stores all of my data. Not really an app, rather this is the foundational data store that integrates across all sources
The Apple Workout app records my workouts. Although there are some better, specialized apps, pressing the Action Button on my Ultra and starting a workout is so convenient that I’m sticking with Workout. The onscreen stats on the watch are more than sufficient for my needs
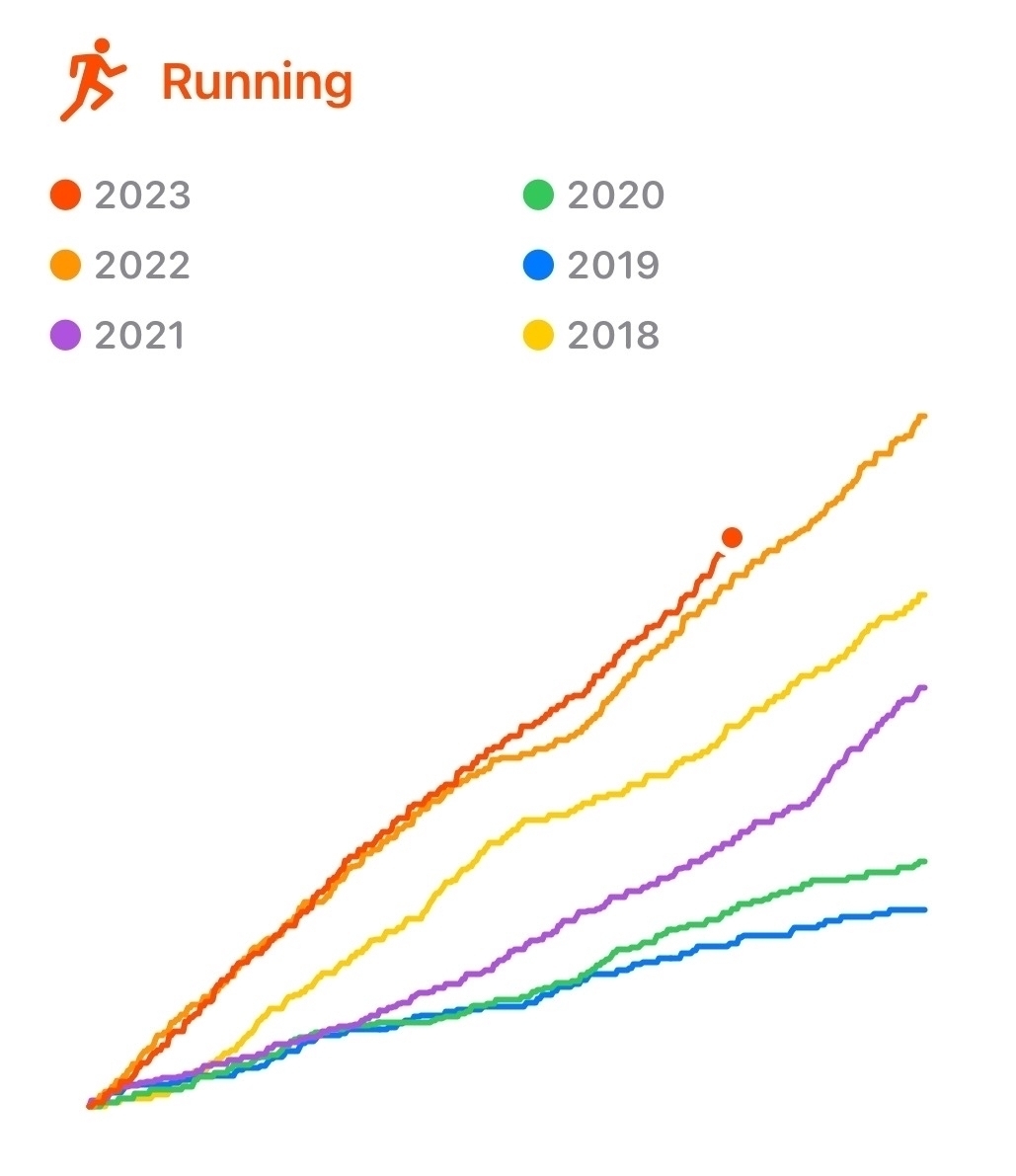
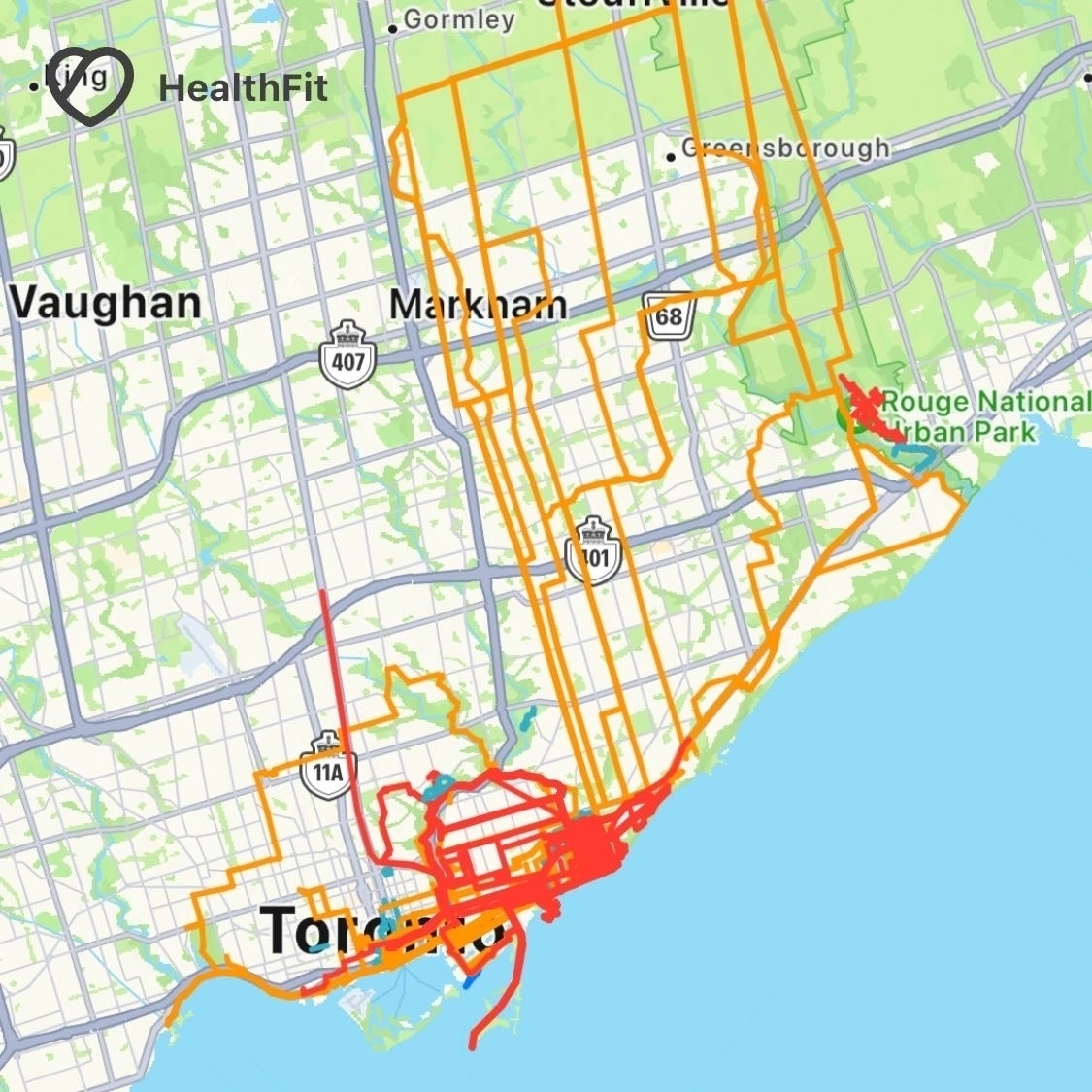
HealthFit is for viewing workout data and general fitness trends. I prefer HealthFit’s details to Apple Health’s. As the screenshots below demonstrate, HealthFit provides useful overviews of everything I’ve done recently. I also use HealthFit to selectively send completed workouts to Strava
Strava is for my local community. Seeing what my friends are up to and cheering them on is part of staying motivated for the training. Strava does have a good set of statistics and summaries. Overall, though, I prefer HealthFit’s design and privacy
Recover sends me targeted mobility and recovery sessions, based on my recent activity. This is the only reason I’m currently paying for a Strava subscription. However, Strava is rather expensive if this is all I’m paying for and Recover breaks principles 1 and 3. So, I don’t think this one will last much longer
Training Peaks is exclusively for getting workouts from my coach. There’s way more potential with this app. I’m just not using any of it
Zwift Companion is well named. I use it to join Zwift events and as a second screen while Zwifting.
That’s currently it for the portfolio. Being able to consolidate all of my data into Apple Health really frees me up to try new apps without worrying about data lock in. Despite this freedom, I’m comfortable with the current set and don’t plan to switch things up anytime soon.
Finished reading: Termination Shock by Neal Stephenson is pretty good. Nowhere near as visionary as Anathem or Seveneves, though tighter than _Fall; or Dodge in Hell_📚
🍿 I enjoyed Fathom (2021), a documentary about attempts to communicate with whales. Pairs well with Fathoms by Rebecca Giggs
Discussions about transit often end up about funding. To help make these discussions productive, I was pleased to co-author a paper through the Transportation Association of Canada titled Importance of Transportation Funding: Framing the Issues.
Transportation funding is becoming an important topic of discussion at all levels of Transportation Association of Canada (TAC) councils and committees, reflecting discussions that are taking place throughout the Canadian transportation community. The fundamental needs are to maintain and upgrade the country’s aging transportation system while adding new infrastructure to meet the demands of a growing population and economy. These needs are evolving in the face of new challenges, notably changing funding sources and priorities, climate change impacts on infrastructure resiliency, changes to how the system is used, and accommodating new transportation and communications technologies. These challenges have become sharper with the COVID-19 pandemic-induced disruptions in how people and goods move and in shifts in revenues and funding priorities. These needs and challenges cover a broad range. They vary across the country, by mode, ownership, responsibility and more. All told, these complexities mean that the needs and challenges are not fully understood. This briefing describes and categorizes these key challenges and opportunities and provides an initial, high-level assessment of the broader range of potential funding sources, approaches and needs. From this review, the briefing identifies knowledge gaps and potential research directions for consideration by the TAC Transportation Finance Committee and other committees and councils to address these gaps.
This didn’t last long. When using Apple Podcasts to listen to Apple Music radio, you don’t see album art and can’t easily add music to your library. Discovery is my main use case. So, though I like the idea of this integration, in practice it doesn’t suit my needs 🎵