A happy 97th birthday to my wonderful grandmother! Such an inspiration to us all


A happy 97th birthday to my wonderful grandmother! Such an inspiration to us all
Back to school with a mixture of excitement and nervousness


I certainly wasn’t expecting Nils Frahm’s next album to be a dub record!
Ball hockey fans

I’m enjoying Watch the Sound With Mark Ronson, a series on music production with episodes on topics like reverb, synthesizers, and sampling
Restocking some essentials 🥃


Currently reading: A Desolation Called Peace (Teixcalaan, 2) by Arkady Martine 📚

I really enjoyed Salvation by Peter F. Hamilton (book 1 of the Salvation Sequence trilogy). A fun blend of sci-fi, detective novel, and alien invasion with a cliffhanger ending📚
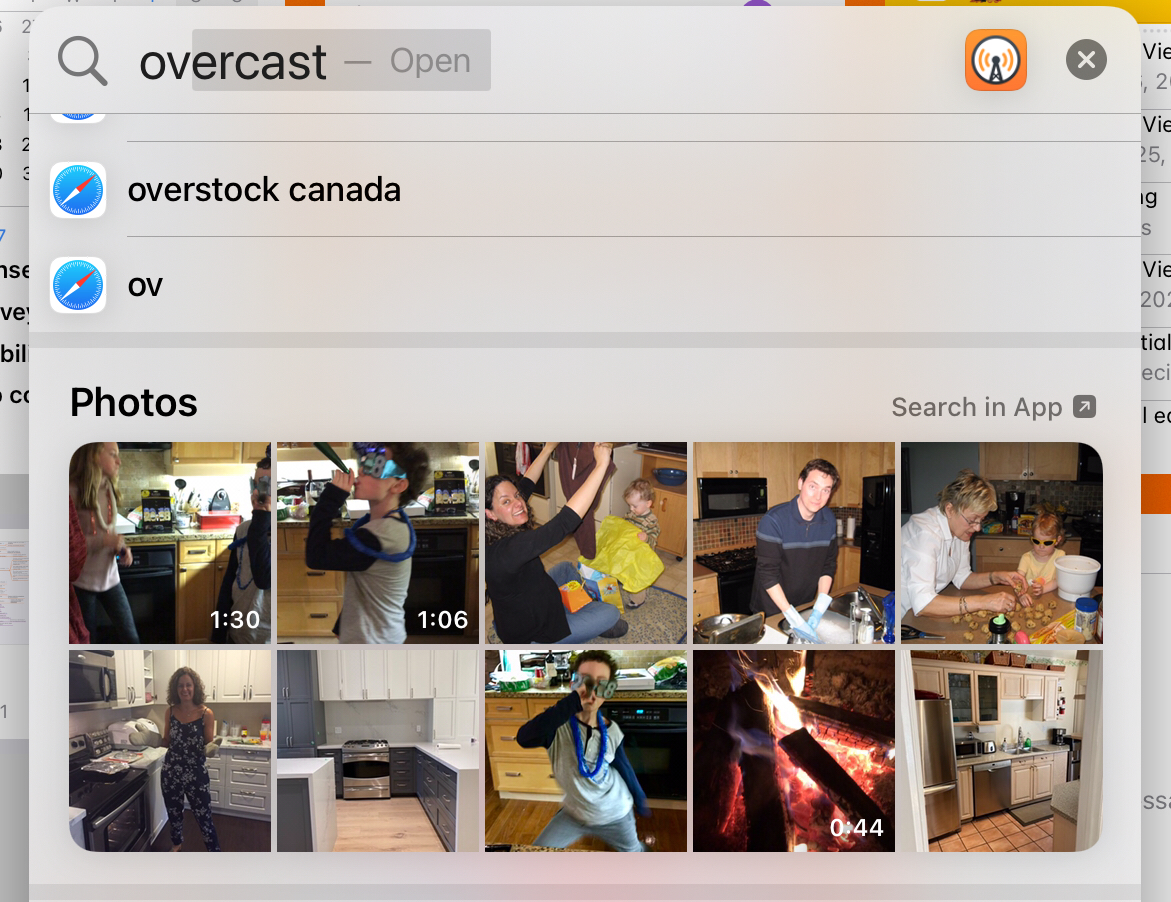
A new game on the iPad: try to guess what term Photos is searching for in Spotlight. Here’s an example where I’m launching Overcast and Photos has used “ov” to find pictures of ovens. This has actually been a great way to uncover how much more sophisticated Photos has become.
My Micro Camp sticker has arrived and looks great! Thanks @burk!

Black Lab Brewery has some great beers, plus I enjoy the branding

Our epistemic crisis is essentially ethical and so are its solutions
Before you know it, people have starkly different views on the matter, and their views are based on perfectly solid research. The point here is not that we can’t know anything, it’s simply that the world is a complex place, and that the search for simplicity is very often what gets us into trouble. For scholars, the most important thing is to strive to present their work in a way that’s as objective as possible (accuracy), and to present a range of reasonable results wherever possible, giving the fullest possible picture (sincerity).
This book caught my eye at the local used bookstore: Pragmatism and Other Essays by William James 📚


Fire Season: Field Notes from a Wilderness Lookout by Philip Connors is an interesting mix of reflections on solitude, the importance of conservation, and American history 📚
Although I only caught day 2 of Micro Camp 2021 live, I really enjoyed the talks. I’ll catch up on day one in a couple of days.
Currently reading: Fire Season: Field Notes from a Wilderness Lookout by Philip Connors 📚
I’m trying to sequence my workouts in a more systematic way to avoid overtraining. I’ve found Training Today really helpful in determining this Readiness To Train (RTT). The app uses data collected by my Apple Watch to provide a straightforward indicator of how ambitious I should be on any particular day.
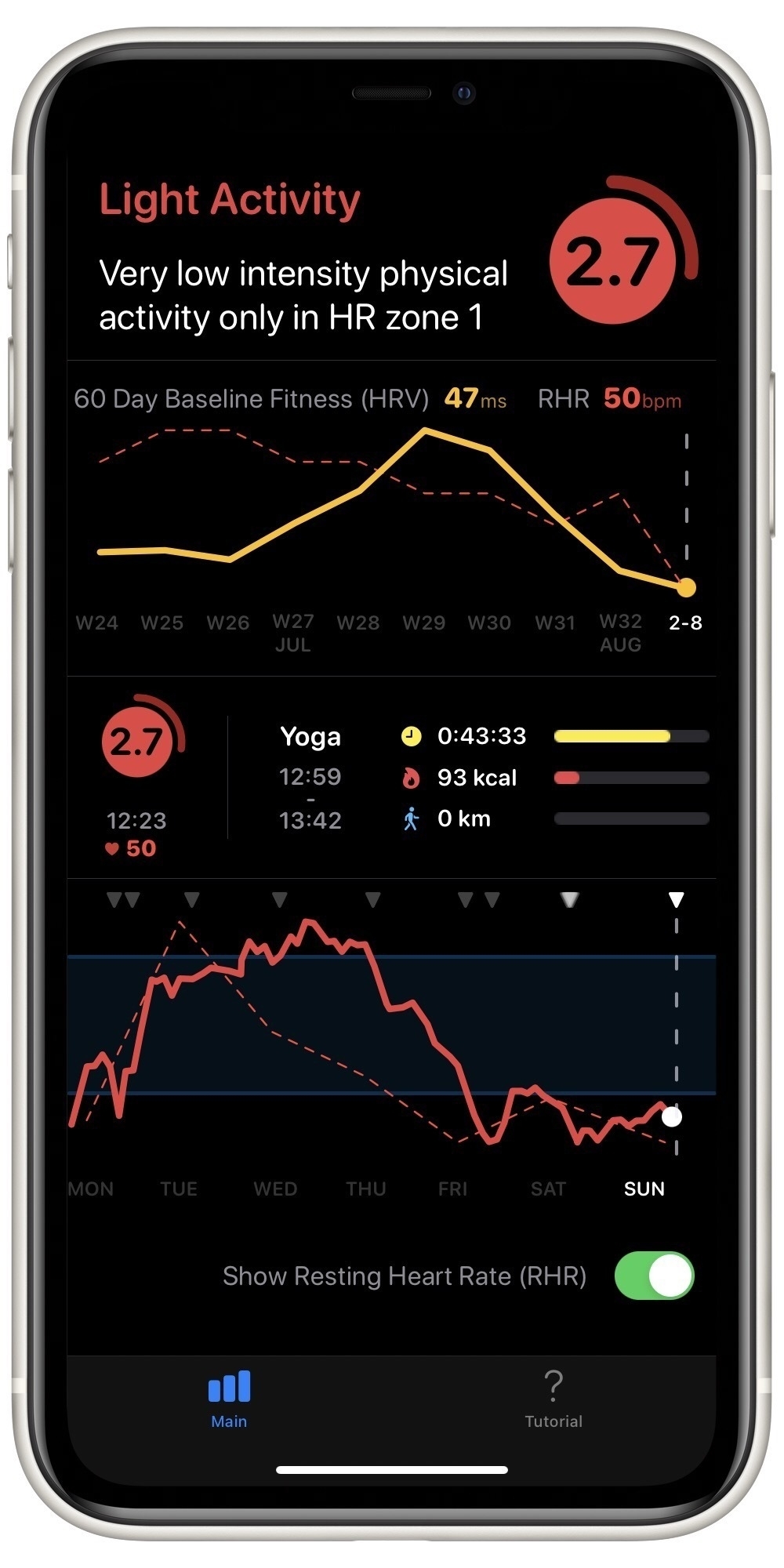
As an example, here’s today’s evaluation:
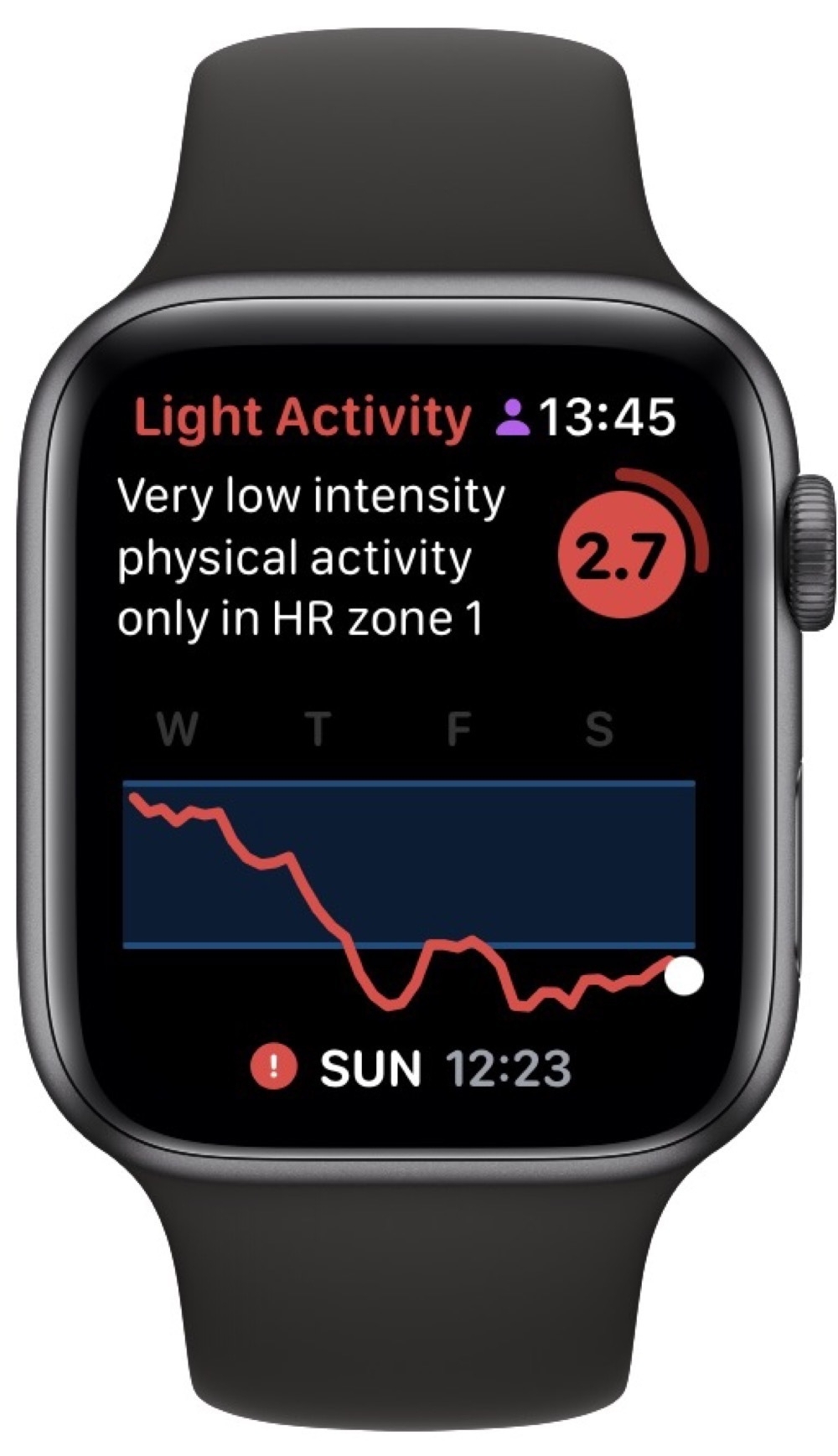
This matches how I feel 🥴. So, today was a good day for some recuperative yoga.
Scrolling back to Thursday, everything looked much better and I put in a good HIIT session:
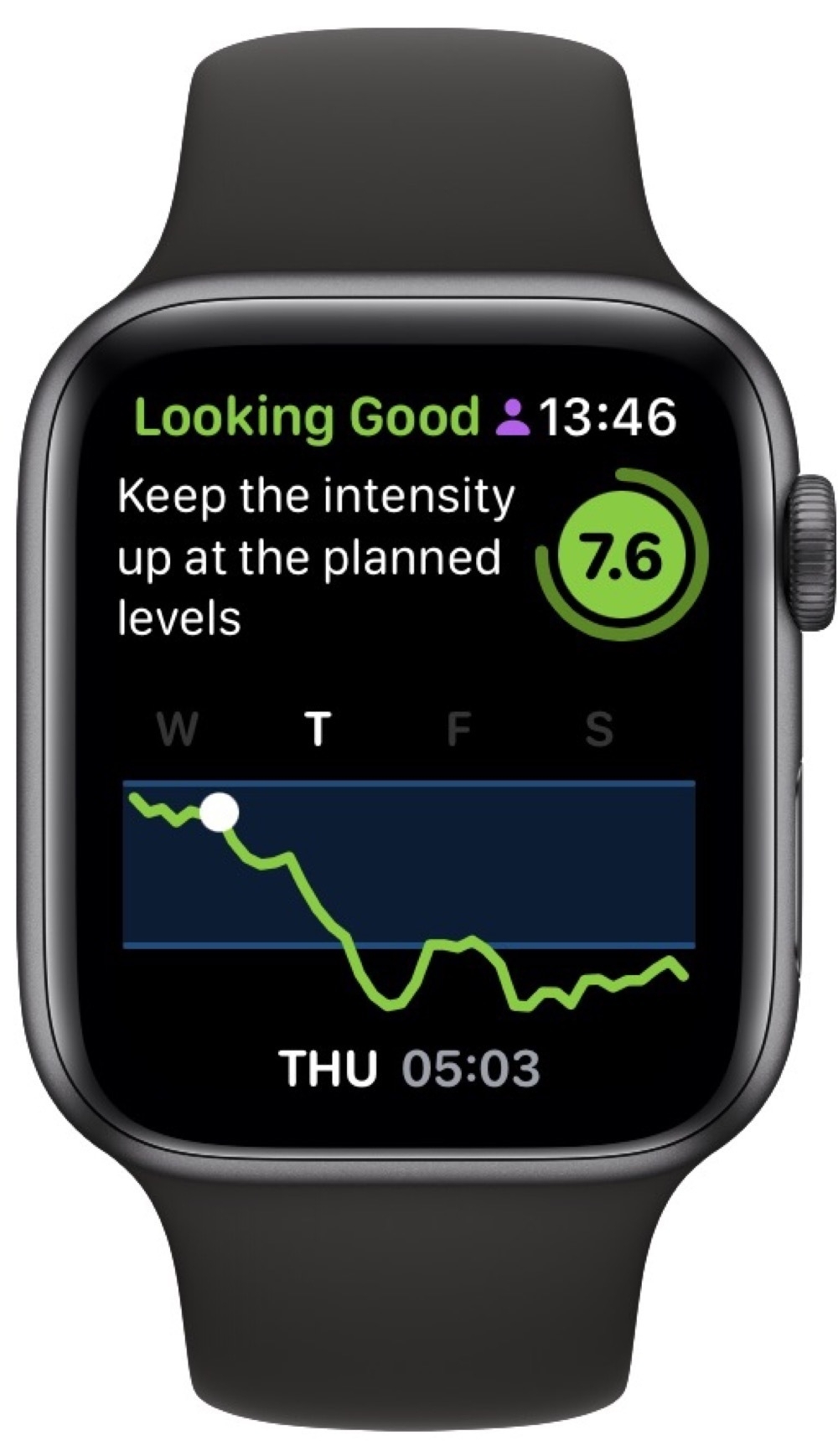
Of course, the whole point of doing this is to adjust my training to match how my body is recovering. I clearly didn’t do this on Friday. Rather than catch up on some sleep, I choose to do a moderate workout and my RTT stayed on the floor. Not great, considering I’d signed up for an intense One Academy Endure Challenge on Saturday. I managed to finish, which is the main goal, but it didn’t feel good.
Comparing my RTT for this week’s Endure Challenge with the last one shows how this indicator can be informative:
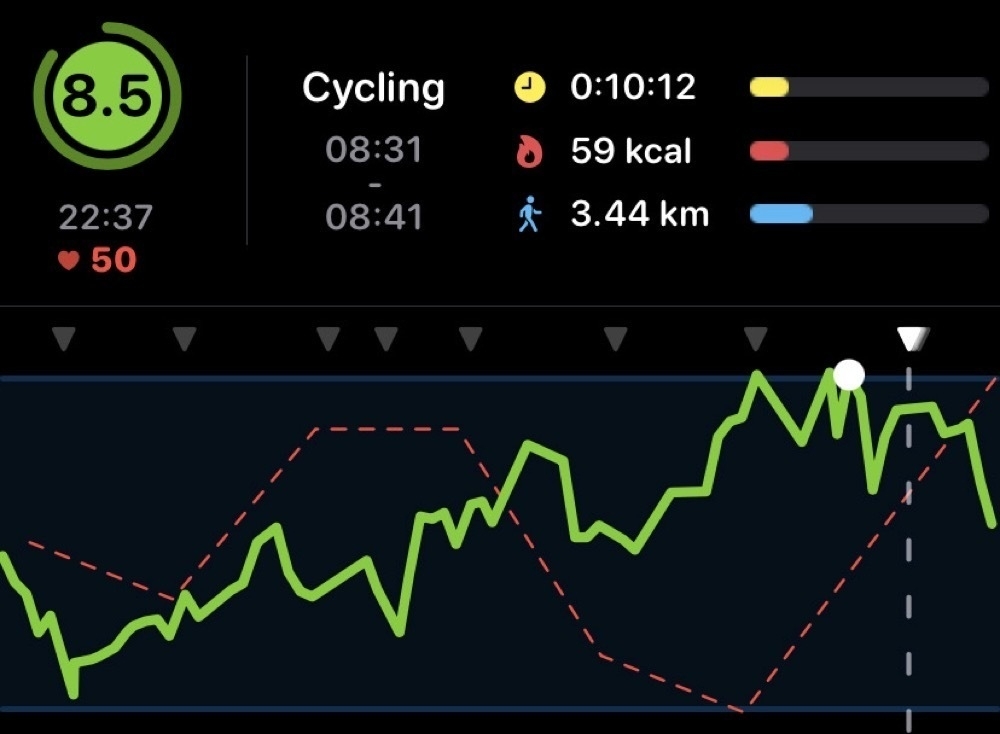
My RTT was much higher back then and I felt really good during the challenge. This gives me comfort that RTT is actually measuring something real and actionable.
The Apple Watch screenshots shown above are part of the free version of the Training Today app. The more detailed chart above is included in a one-time in-app purchase. This gets you details like this:
And a simple widget, shown below on my fitness home screen:
I really like the focussed simplicity of Training Today, along with the straightforward one-time purchase. My Apple Watch is collecting lots of data about me and I’m glad I can use it to better manage my fitness.

Excession by Iain M. Banks is a great read with a fun mix of space opera, humour, morality, and mystery 📚
A great video on the Standard Model of physics
Really well done and fascinating video on The Sounds of Space